
Python爬虫技巧:完美提取文章内容
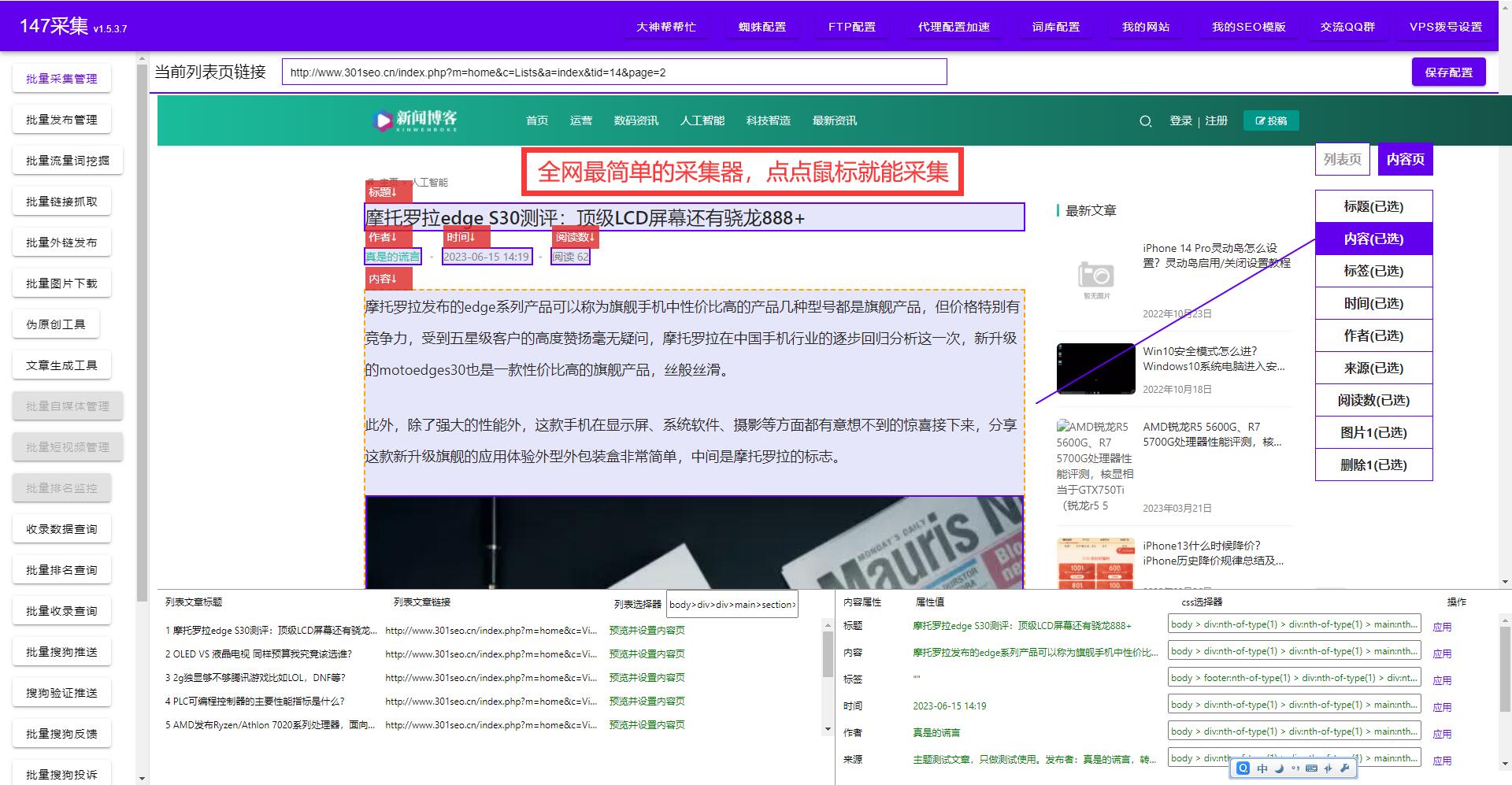
随着互联网的迅速发展,人们对海量信息的需求也越来越大。然而,网络上的信息大多以网页形式存在,我们需要对这些网页进行解析和抓取,提取出其中的有用内容。本文将介绍如何使用Python爬虫技巧来完美提取网页中的文章内容,并分享一些实用的方法和工具。
一、为什么需要文章提取?
在进行信息检索或数据分析时,常常需要从网页中提取出文章内容。文章提取可以帮助我们过滤掉SEO、导航、侧边栏等无关信息,从而获取更加干净、纯粹的文章内容。对于需要进行文本挖掘、自然语言处理等任务的开发者来说,获取规范化的文章内容是非常重要的。
二、Python爬虫实现文章提取的方法
1.使用正则表达式 正则表达式是一种强大的文本匹配工具,可以根据特定的规则提取出网页中的内容。但是,由于网页的结构多变,且存在标签嵌套等问题,使用正则表达式提取文章内容可能会比较复杂和繁琐。
2.使用第三方库 Python中有一些优秀的第三方库可以帮助我们提取文章内容,其中最流行的有BeautifulSoup和PyQuery。这些库可以解析HTML或XML文档,并提供了简单易用的API来快速定位和提取所需内容。
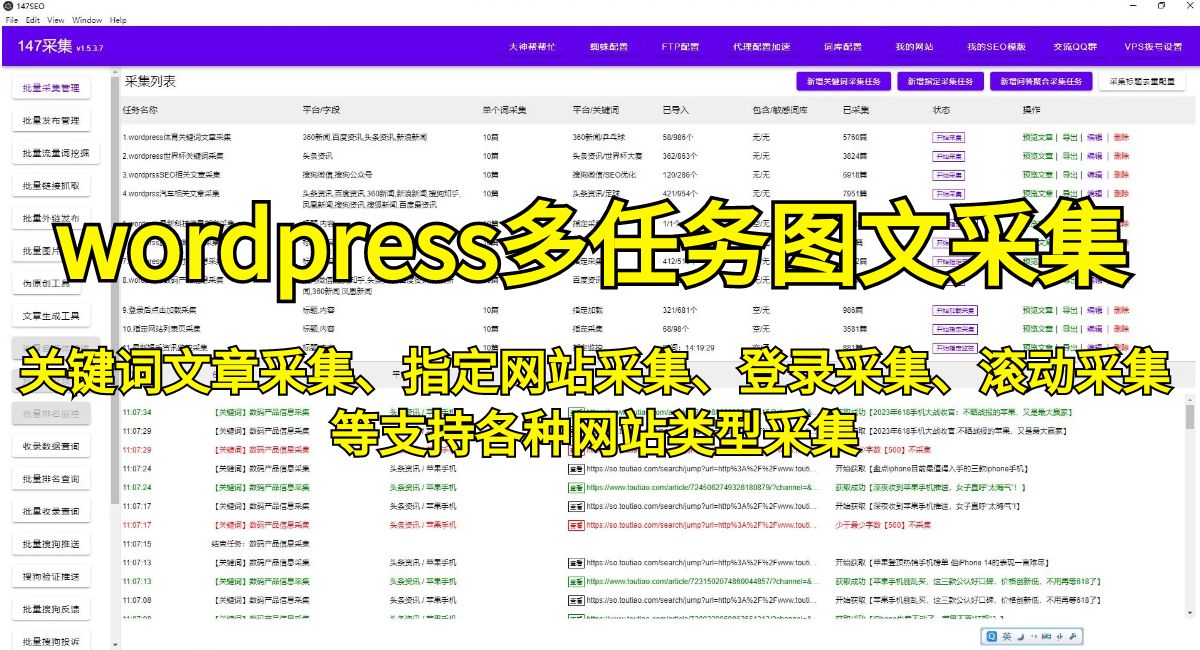
3.使用机器学习模型 近年来,基于机器学习的文章提取方法也得到了广泛应用。通过训练,机器学习模型可以学会如何从网页中提取出文章内容。常用的机器学习算法包括决策树、随机森林和支持向量机等。
三、实际案例及工具推荐
1.BeautifulSoup BeautifulSoup是Python中最受欢迎的HTML和XML解析库之一,可以帮助我们轻松解析网页并提取所需内容。其简明的API和灵活的处理方式使得文章提取变得简单而高效。
2.PyQuery PyQuery是一个与jQuery类似的库,同样适用于解析HTML和XML文档。它提供了类似于CSS选择器的语法来定位和提取元素,非常方便易用。
3.Readability Readability是一个开源的文章提取工具,它可以自动从网页中提取出干净易读的文章内容。它底层使用了类似机器学习的算法,对于大多数网页都能够较好地进行提取。
四、总结
本文介绍了使用Python爬虫技巧来完美提取文章内容的方法和工具。通过正则表达式、第三方库和机器学习模型,我们可以根据需求选择合适的方法来实现文章提取。推荐使用BeautifulSoup、PyQuery和Readability等工具,它们在文章提取方面都有着良好的表现。希望本文能够对Python爬虫初学者提供一些参考和指导,让你在实际应用中能够轻松提取出所需的文章内容。



