
如今,PPT已经成为了各行各业中必备的工作工具之一,它可以清楚地传达信息、展示数据,并通过图表和图像等元素增强观众对内容的记忆。在我们的日常工作和学习中,经常需要查找和使用各种各样的PPTZY。但是,市面上能够免费获取高质量的ZY却并不多,我们往往需要花费大量的时间去搜索和筛选。
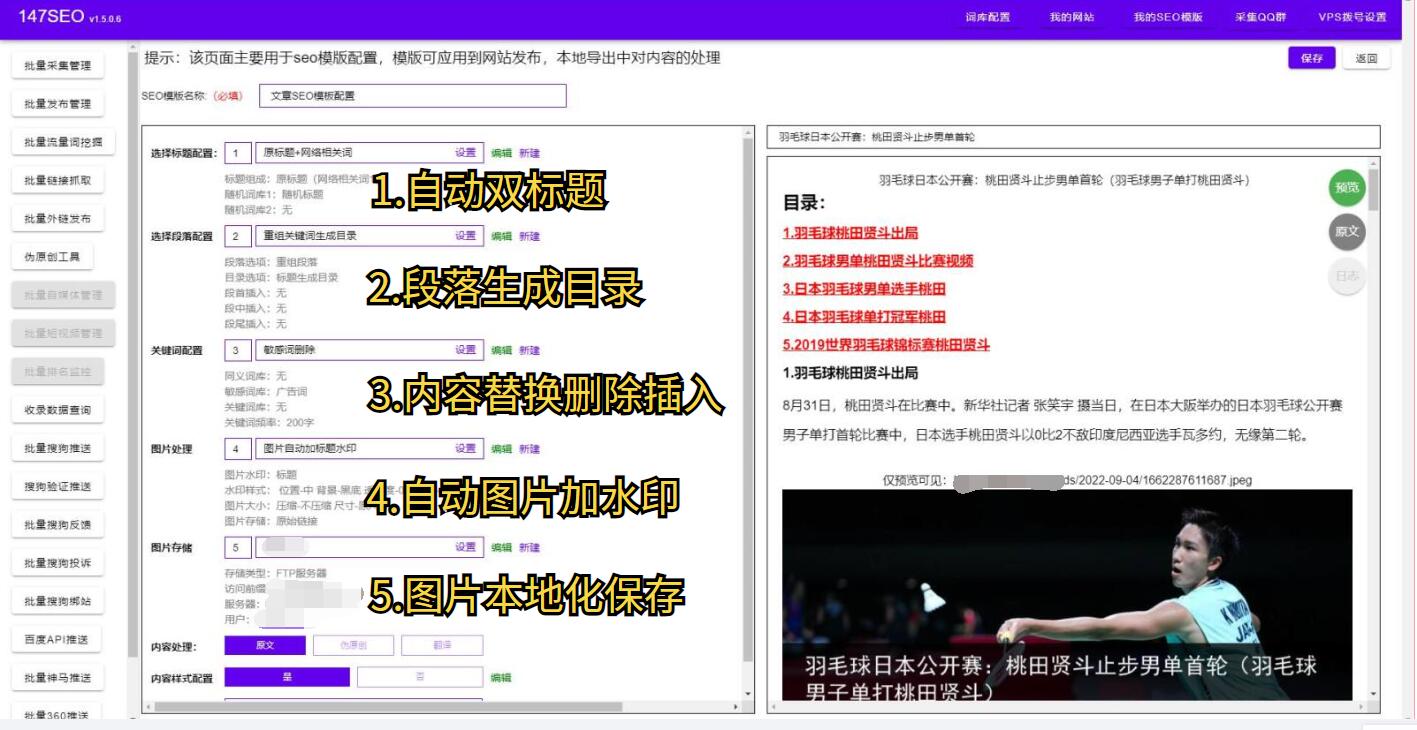
好在,我们有一种非常方便和高效的方式来解决这个问题——使用Python编写一个爬虫程序。Python是一种强大的编程语言,它具有简洁、易读的语法,且有着丰富的第三方库支持。借助Python的爬虫库,我们可以很容易地从互联网上抓取任意网页的PPTZY。
要实现这个目标,我们首先需要安装Python的相关库,比如requests、beautifulsoup、lxml等。安装完成后,我们就可以开始编写爬虫程序了。首先,我们需要指定要抓取的目标网页,然后通过发送HTTP请求获取网页的HTML代码。接下来,我们可以使用beautifulsoup库来解析HTML代码,提取出我们所需的幻灯片链接。最后,我们只需要根据获取到的链接,将PPT文件下载到本地即可。
当然,在编写爬虫程序的过程中,我们也需要关注一些道德和规则的问题。在抓取网页数据时,我们需要确保自己的行为合法合规,不要侵犯他人的权益。我们可以通过robots.txt文件来了解网站的抓取规则,以及使用适当的延时和请求头信息,避免给网站造成过大的负载。
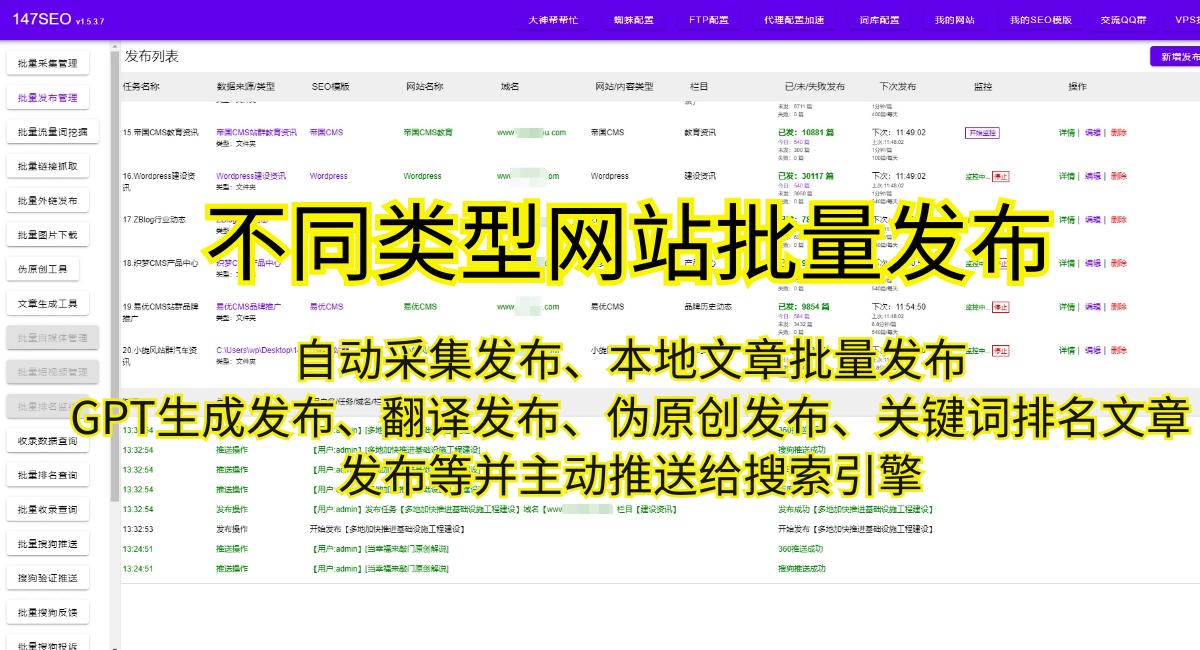
此外,爬虫程序的稳定性和性能也是需要考虑的因素之一。一方面,我们需要充分了解目标网站的结构和特点,以便编写出高效稳定的爬虫程序。另一方面,我们可以通过设置合理的反爬机制和异常处理逻辑,提高爬虫程序的鲁棒性和可靠性。
总结一下,使用Python编写爬虫程序来抓取任意网页的PPTZY,可以省去我们大量的搜索和筛选时间,使我们能够更加便捷地获取所需的幻灯片。当然,在使用爬虫程序的过程中,我们要遵守道德和规则的规定,避免对他人的权益进行侵犯。同时,我们还需要充分了解目标网站的结构和特点,以及提高爬虫程序的稳定性和性能。希望本文能够对你有所帮助,让你更加高效地使用Python爬虫来获取PPTZY。



