
Python网页数据采集是当今信息时代中不可或缺的重要技术。随着互联网的快速发展,大量的信息被存储在各个网页上,而网页数据采集技术可以帮助我们从这些网页上获取并提取有价值的数据,进一步应用于各种领域的数据分析和决策支持中。
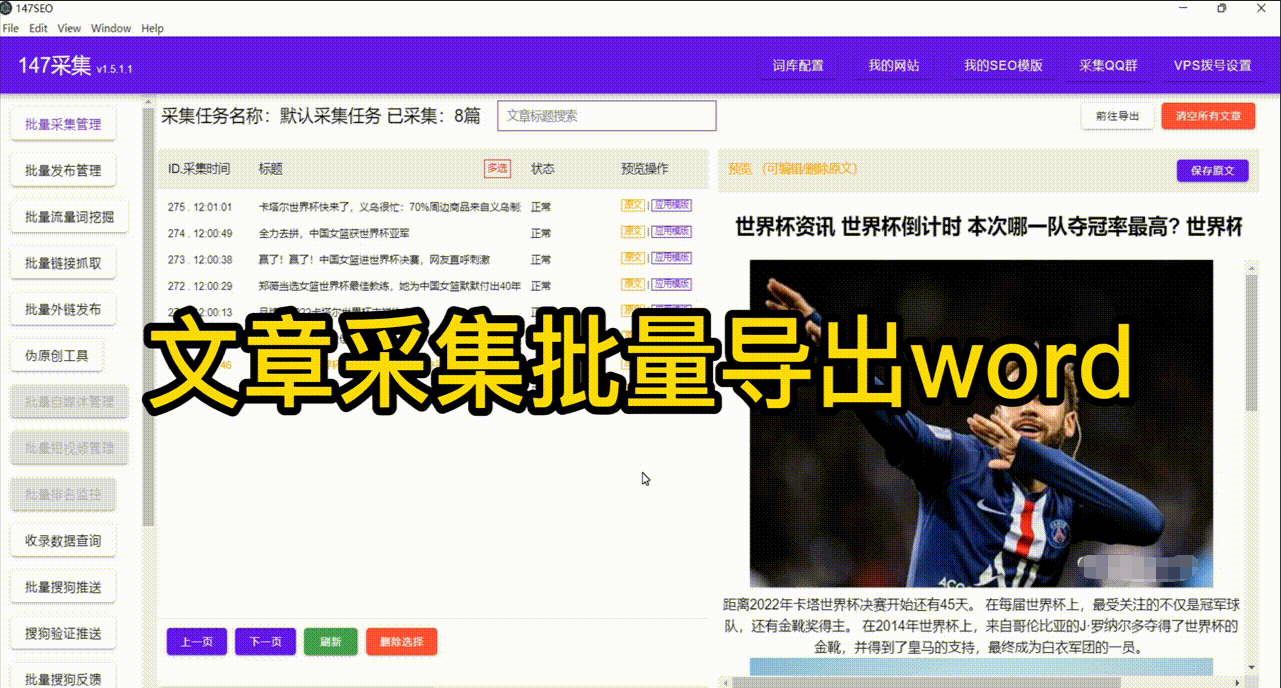
Python作为一种简单易用但功能强大的编程语言,成为了网页数据采集的首选工具。它提供了丰富的库和工具,能够帮助开发者快速、高效地实现网页数据的自动化采集和处理。
首先,我们需要明确数据采集的目的和需求。通过定义目标网页的URL,并使用Python中的requests库发送HTTP请求,我们可以获取网页的HTML内容。接下来,利用Python中的BeautifulSoup库可以方便地对获取到的HTML内容进行解析,从而提取出网页中的各种数据。
网页数据采集不仅可以获取文本数据,还可以获得图片、shiping、音频等多媒体文件。Python中的urllib库和第三方库如scrapy等提供了强大的功能,可以帮助我们下载和处理这些多媒体文件。
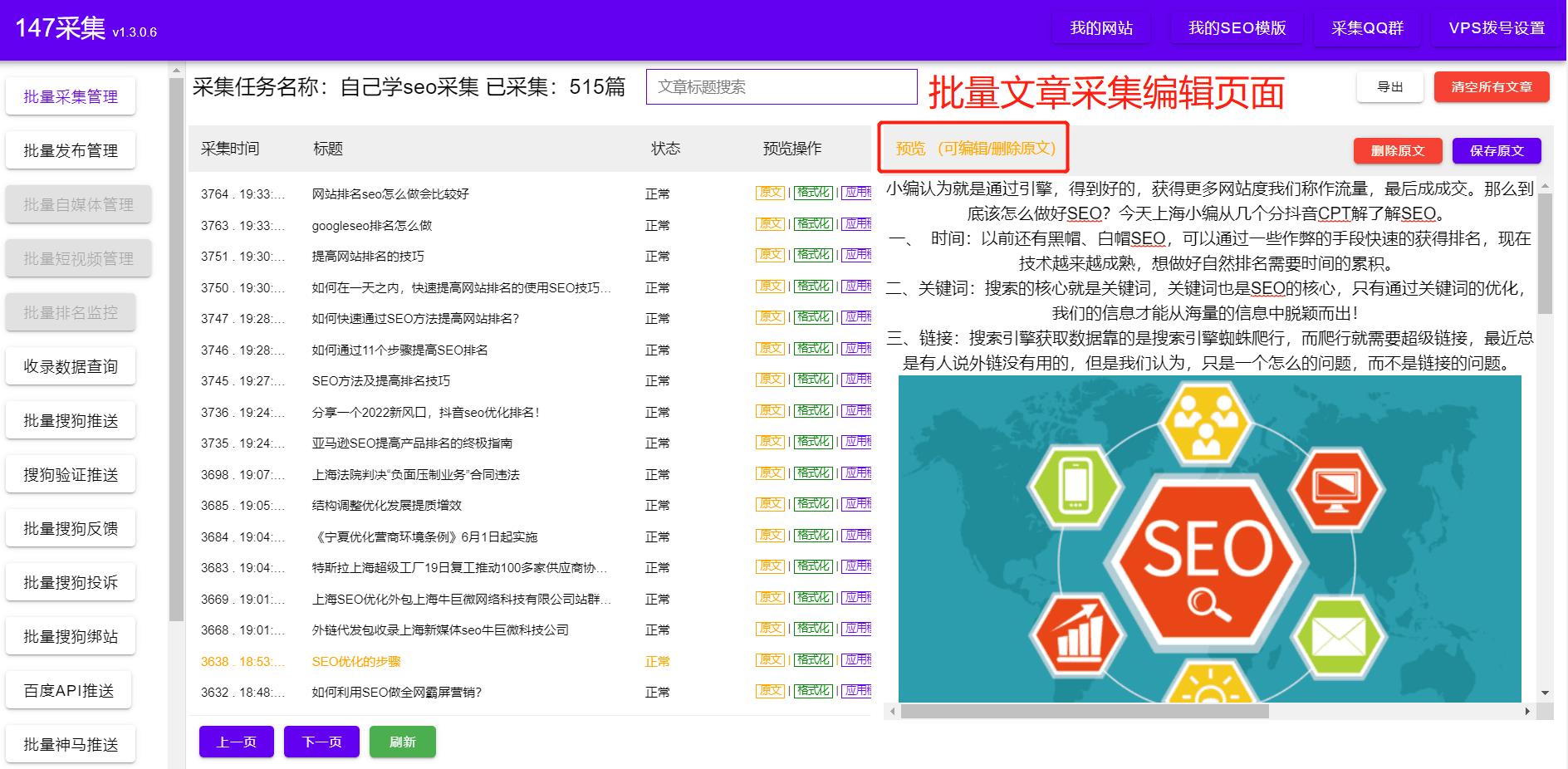
在数据采集的过程中,我们还可能需要模拟浏览器行为,实现对动态网页的数据获取。Python中的selenium库可以模拟用户在浏览器中的操作,实现动态网页的数据采集。
一旦我们获取到了网页数据,我们还需要进行数据清洗和处理,以便进一步应用于数据分析和决策支持中。Python中的pandas、numpy等数据处理库提供了丰富的函数和方法,可以帮助我们对数据进行清洗、过滤、转换等操作,实现数据的预处理和分析。
除了数据采集和处理,Python还可以与数据库进行交互,将采集到的数据存储到数据库中,方便后续的数据管理和分析。Python中的sqlite、MySQL、MongoDB等数据库连接库可以方便地与各种数据库进行交互。
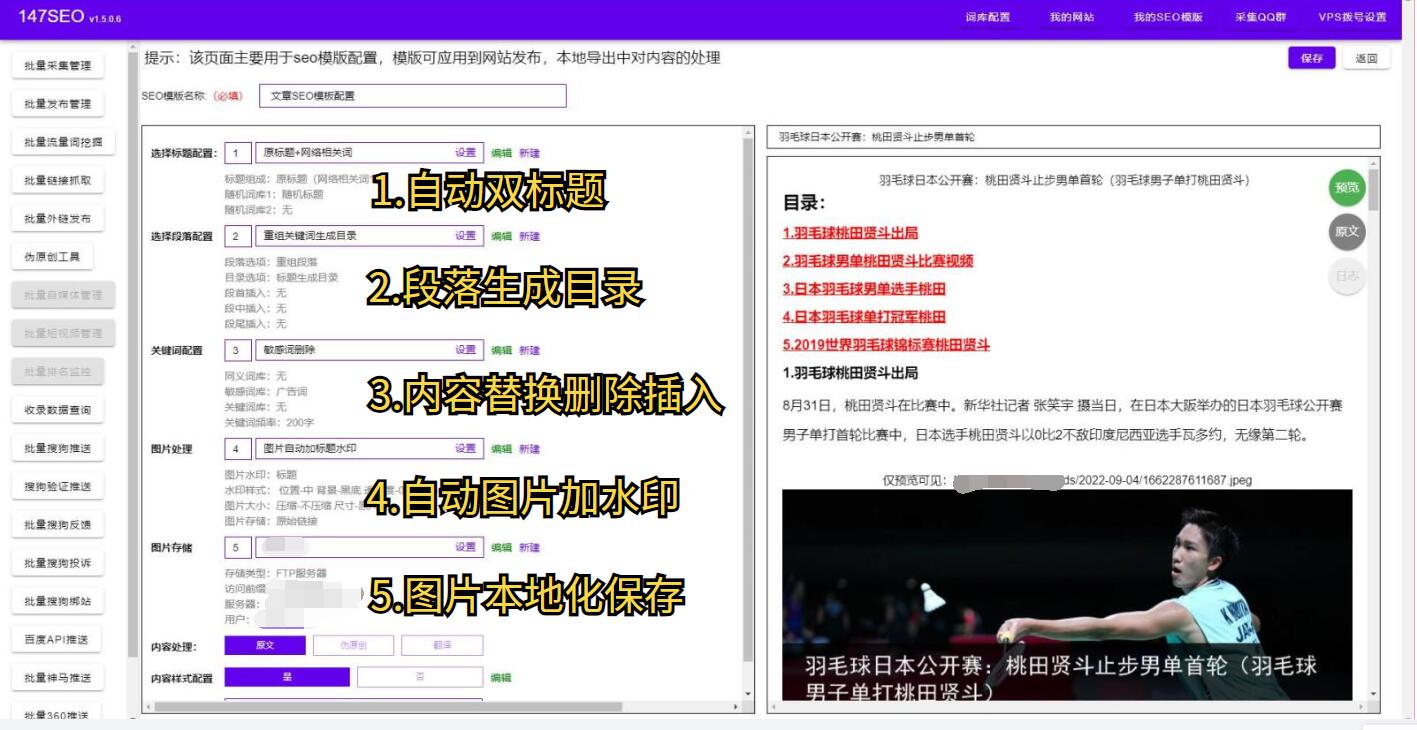
总而言之,Python网页数据采集是一项非常重要的技术,它可以帮助我们从海量的网页数据中提取有价值的信息,实现数据的高效处理和分析。利用Python的丰富库和工具,我们可以快速、高效地进行网页数据采集的开发。同时,Python的数据处理和数据库交互功能也为我们进一步分析和利用采集到的数据提供了便利。掌握Python网页数据采集技术,将为我们在信息时代中的工作和学习带来巨大的便利和效益。



