
随着互联网的快速发展,数据已成为了当今社会最为宝贵的ZY之一。在众多的数据源中,数据库是存储和管理数据的重要工具。为了更好地利用数据库中的数据,有时我们需要将数据库中的数据导出到其他pingtai或进行数据分析。本文将介绍使用Python编写数据库爬虫的方法,帮助读者了解如何高效地获取数据库中的数据。
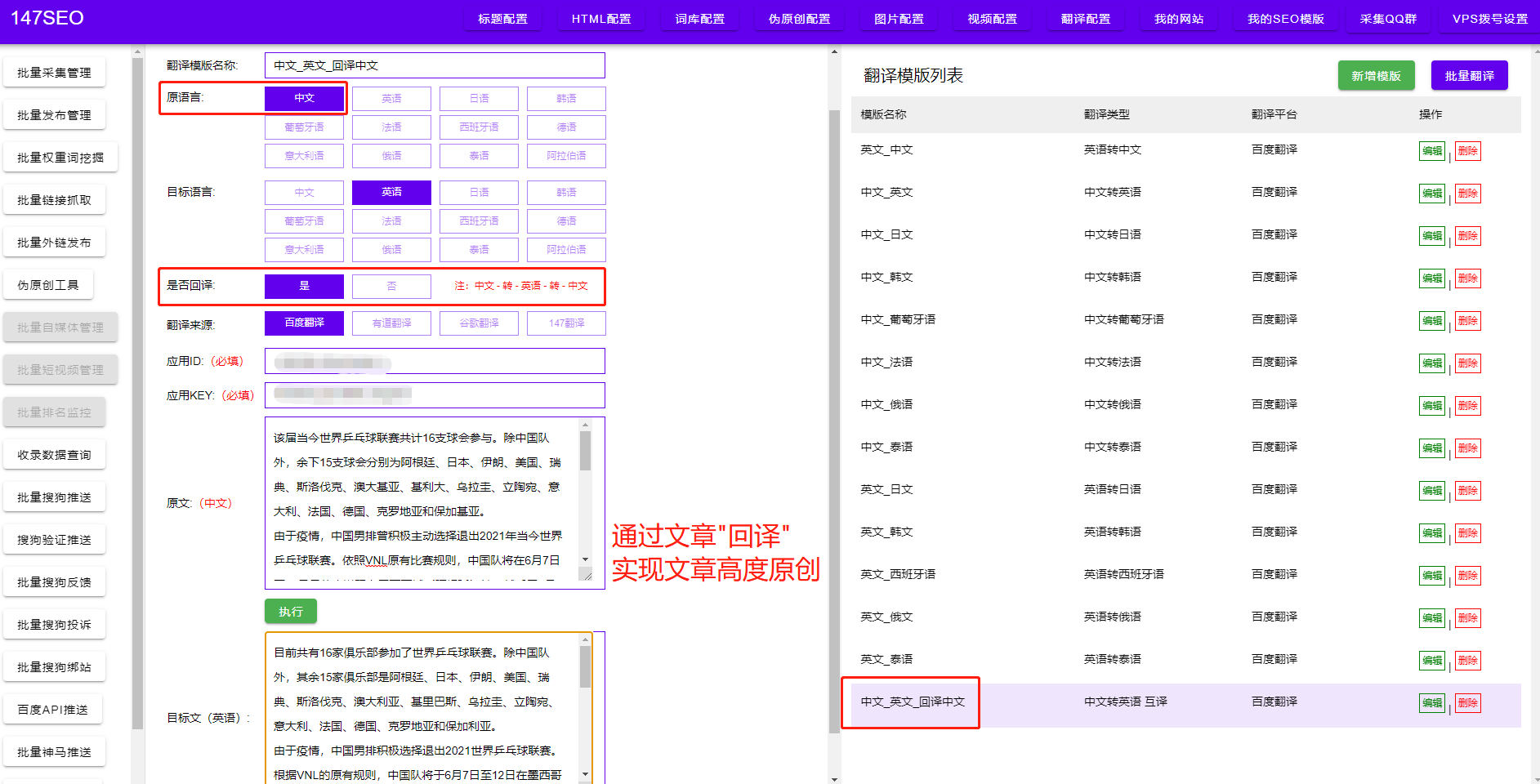
首先,我们需要选择适合的Python库来连接数据库。常用的有MySQLdb、SQLite和psycopg2等库,可以根据自己使用的数据库类型选择对应的库。在安装完成所需的库之后,我们可以使用Python提供的API来连接数据库。
连接数据库的第一步是导入所需的库,例如使用SQLite3库连接SQLite数据库可以使用以下代码:
importsqlite3
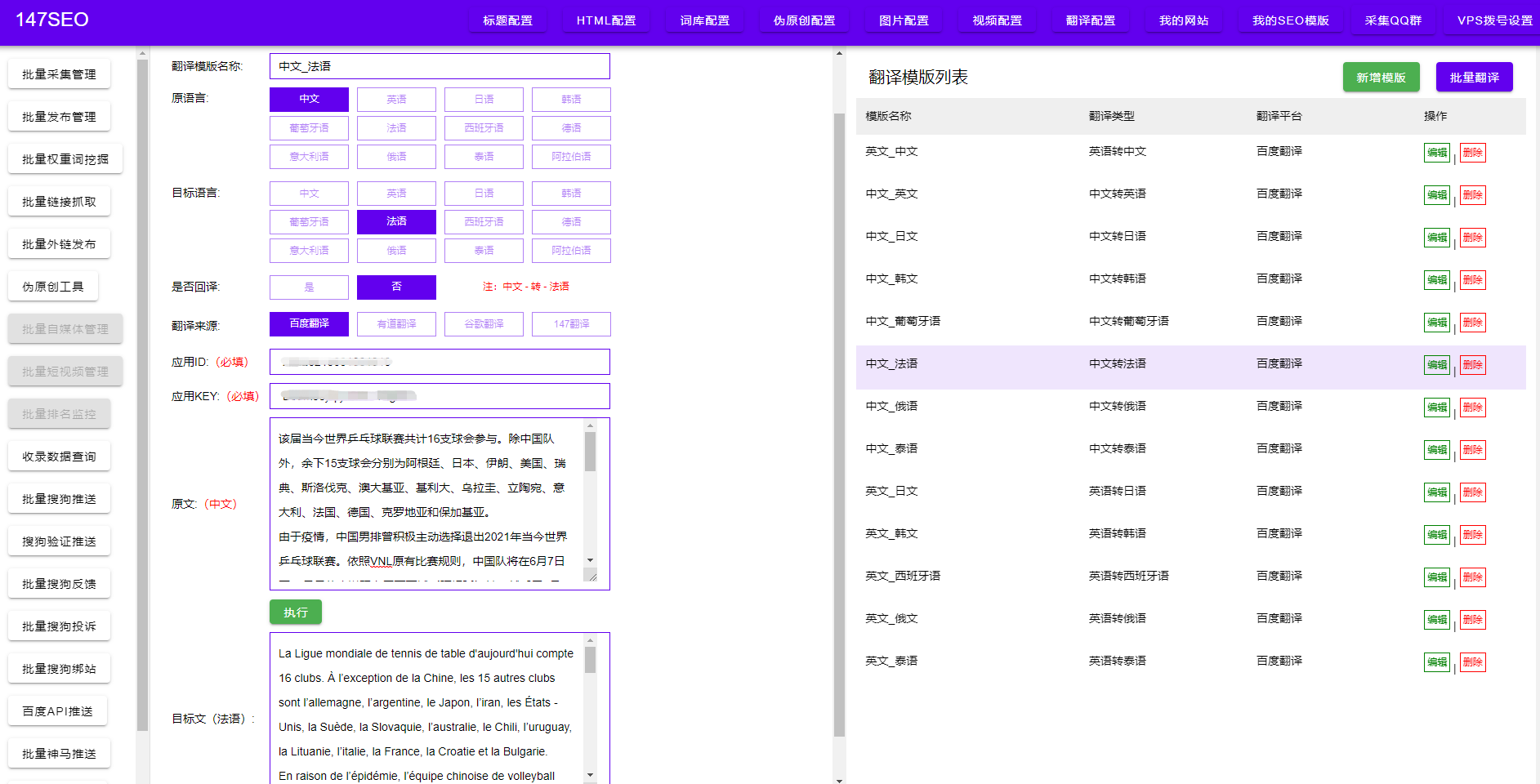
接下来,我们需要建立与数据库的连接。通过调用相应数据库类的connect()方法,我们可以创建一个数据库连接对象。例如,连接SQLite数据库可以使用以下代码:
conn=sqlite3.connect('database.db')
在建立了连接之后,我们就可以通过数据库连接对象使用SQL语句来进行查询操作。比如,我们想要查询一个名为users的表中的所有数据,可以使用以下代码:

cursor=conn.cursor() cursor.execute('SELECT*FROMusers') result=cursor.fetchall()
上述代码通过cursor对象执行了一条查询语句,并通过fetchall()方法获取了查询结果。我们可以根据自己的需求调用不同的SQL语句来完成各种操作,如插入、更新和删除数据等。
通过上述的查询操作,我们可以获取到数据库中的数据。但是有时候,我们需要将这些数据导出到其他pingtai或进行数据分析。在这种情况下,我们可以将数据保存为CSV或JSON格式。下面以保存为JSON格式为例:
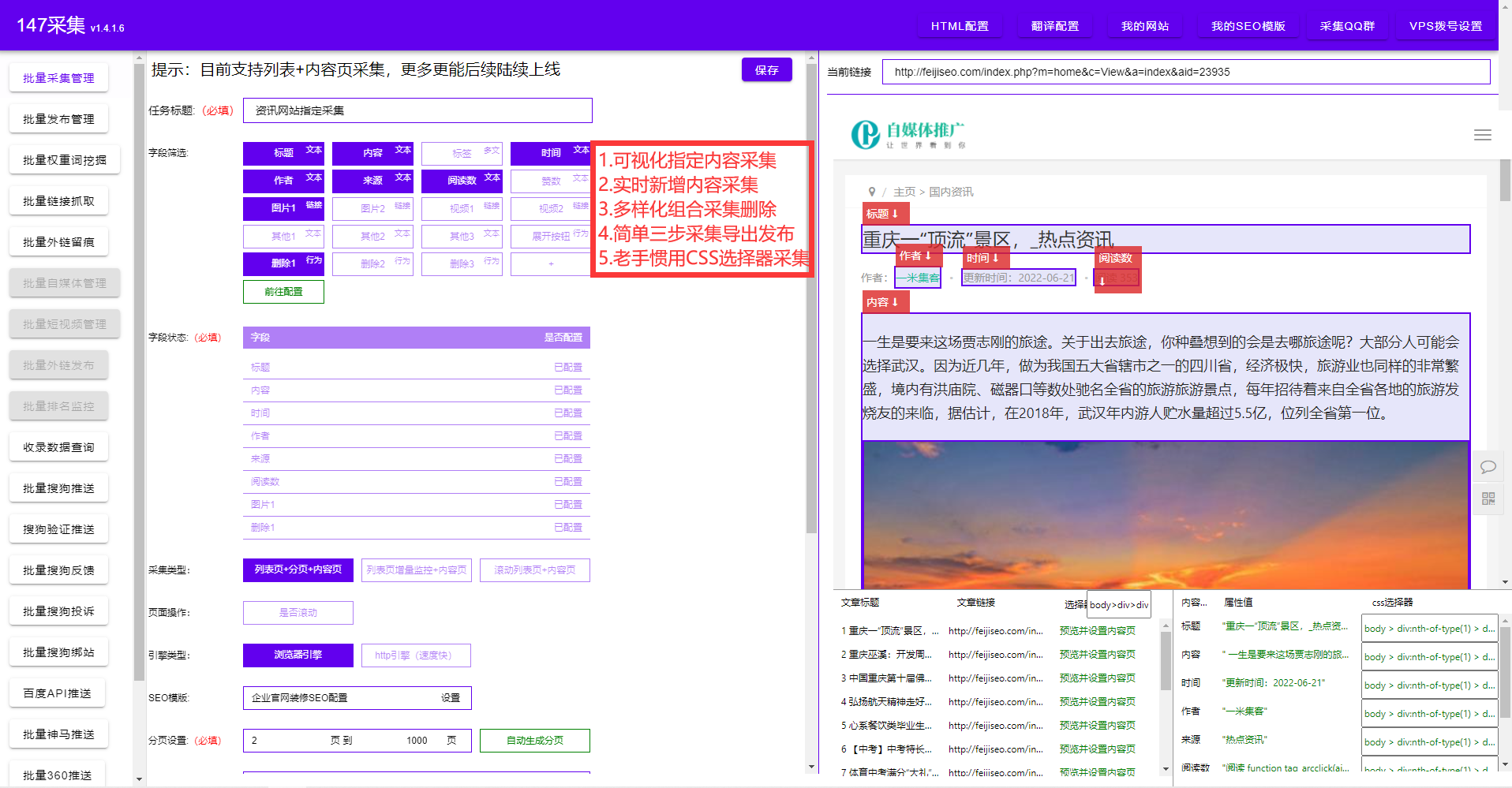
importjson
#将查询结果转换为JSON字符串 json_data=json.dumps(result)
#将JSON字符串保存为文件 withopen('data.json','w')asfile: file.write(json_data)
通过调用json.dumps()方法,我们可以将查询结果转换为JSON字符串。然后,通过打开一个文件并使用'w'模式,我们可以将JSON字符串写入到文件中。这样,我们就可以得到一个包含数据库中数据的JSON文件。
当然,数据库爬虫的应用远不止于此。我们可以通过编写各种爬虫程序来实现更多复杂的操作,如自动化数据抓取、定时任务调度等。通过使用Python作为爬虫的开发语言,我们可以利用其丰富的第三方库和简洁的语法来减少开发成本和提高开发效率。
在编写数据库爬虫的过程中,我们还需注意一些问题,比如隐私数据的保护和爬取数据的合法性。爬取数据可能会涉及到隐私泄露等问题,我们需要注意保护用户的隐私。另外,在爬取数据过程中,应该遵守相关规则法规,并避免对他人的合法权益造成损害。
综上所述,本文介绍了使用Python编写数据库爬虫的方法,帮助读者了解如何高效地获取数据库中的数据。通过选择适合的Python库连接数据库、编写相应的SQL语句,我们可以轻松地操作数据库并将数据导出到其他pingtai。此外,我们还提及了一些注意事项,帮助读者合法、安全地进行数据爬取。



