
Python网络爬虫:采集网页数据的利器
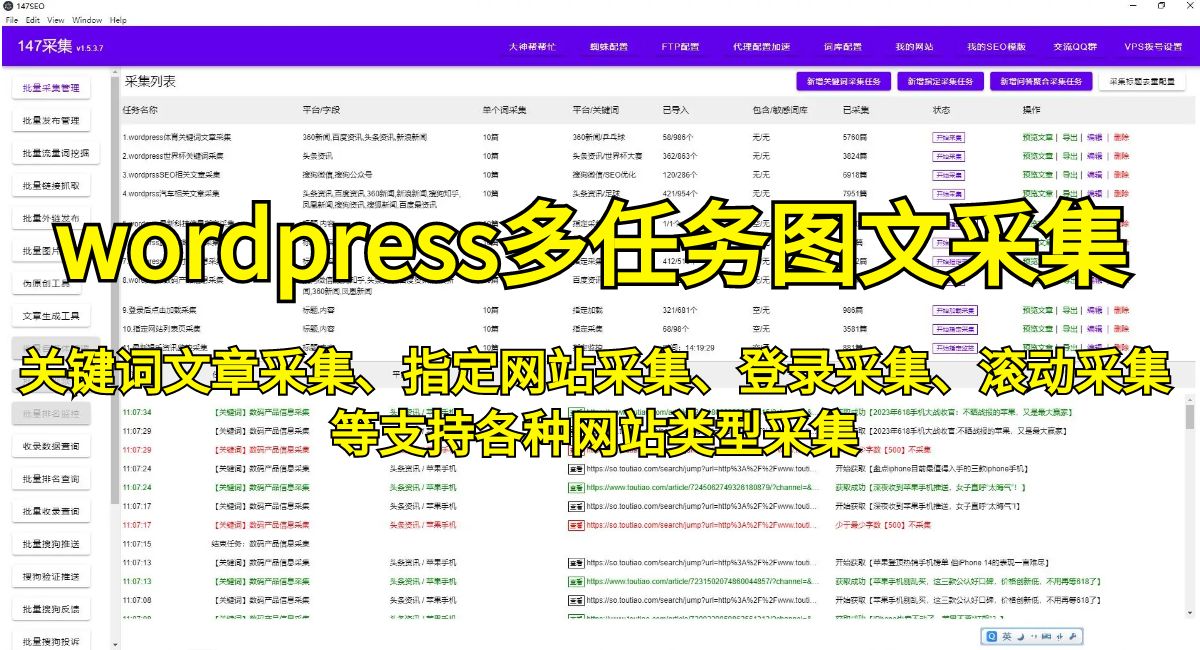
随着互联网的快速发展,数据成为一种非常重要的资产,对于企业的决策分析和市场调研来说,准确的数据是取得成功的关键。然而,网页数据的获取却并不是一件容易的事情,需要通过一定的技术手段来实现。而Python作为一种简单易用且功能强大的编程语言,成为了大多数开发者首选的工具之一。
为什么选择Python进行网页数据采集?
首先,Python具有极其丰富的第三方库,例如BeautifulSoup和Scrapy,这些库提供了强大的功能,能够方便地解析HTML和XML文件,从而获取想要的数据。
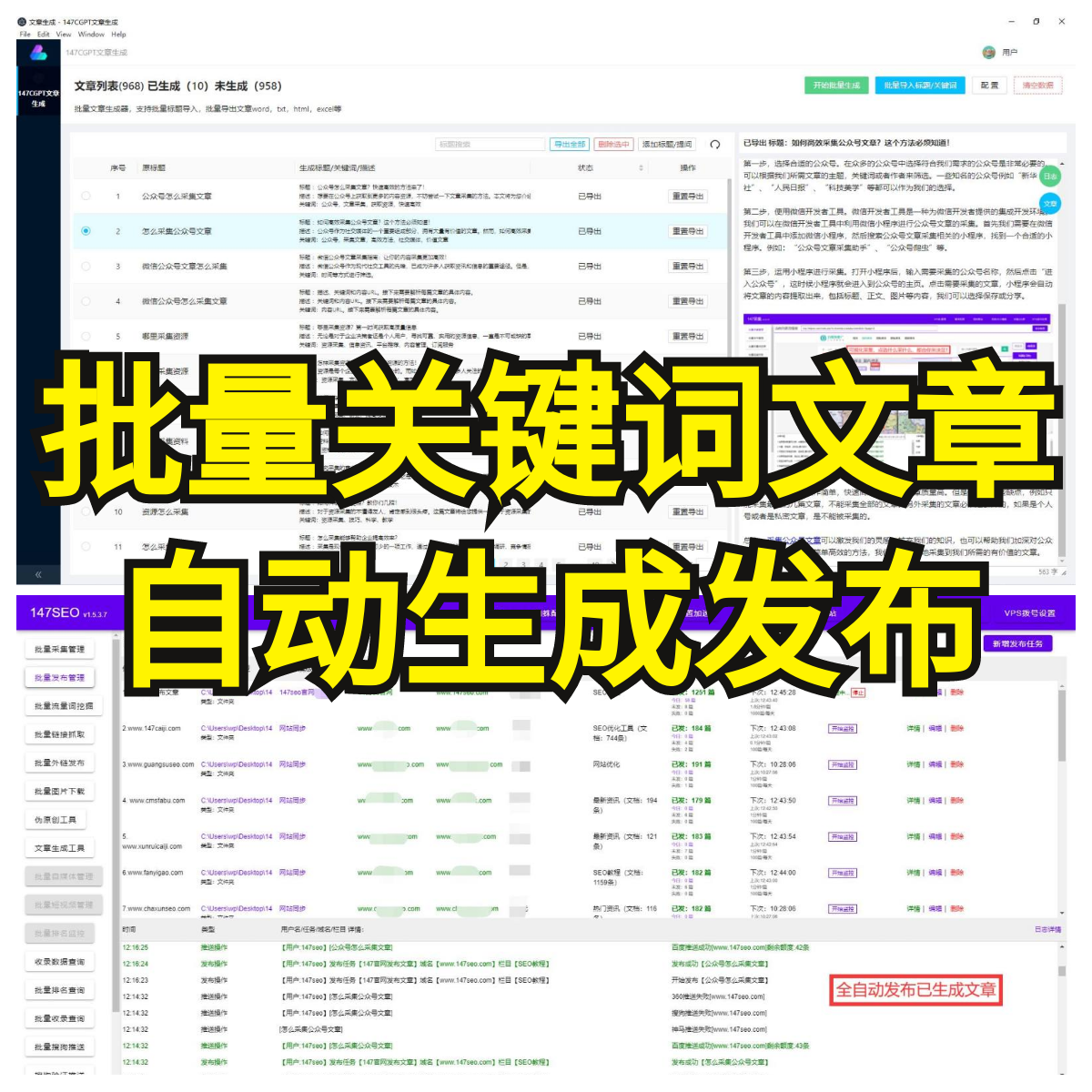
其次,Python拥有简洁明了的语法,对于初学者来说容易上手。通过Python编写的爬虫程序,不仅逻辑清晰,还能够快速开发出高效稳定的爬虫工具。
此外,Python还有强大的网络编程能力,可以自由地获取互联网上的各种ZY。利用Python进行网页数据采集不仅可以获取文本信息,还可以获取图片、shiping甚至是动态内容,为数据分析提供更丰富的ZY。
Python网络爬虫的基本原理
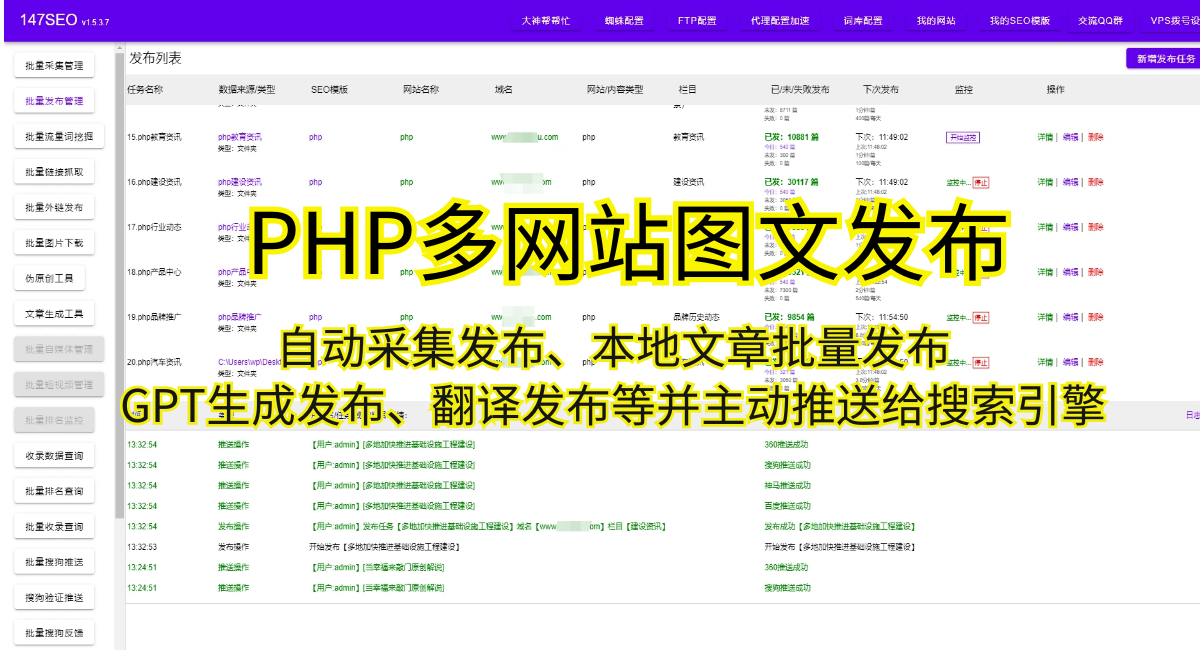
Python网络爬虫的基本原理是模拟浏览器的行为,通过发送HTTP请求访问目标网页,然后解析网页的HTML代码,提取所需的数据。
具体而言,Python爬虫程序包括以下几个步骤:
1.发送HTTP请求:使用Python内置的urllib库或第三方库requests发送HTTP请求,获取目标网页的源代码。
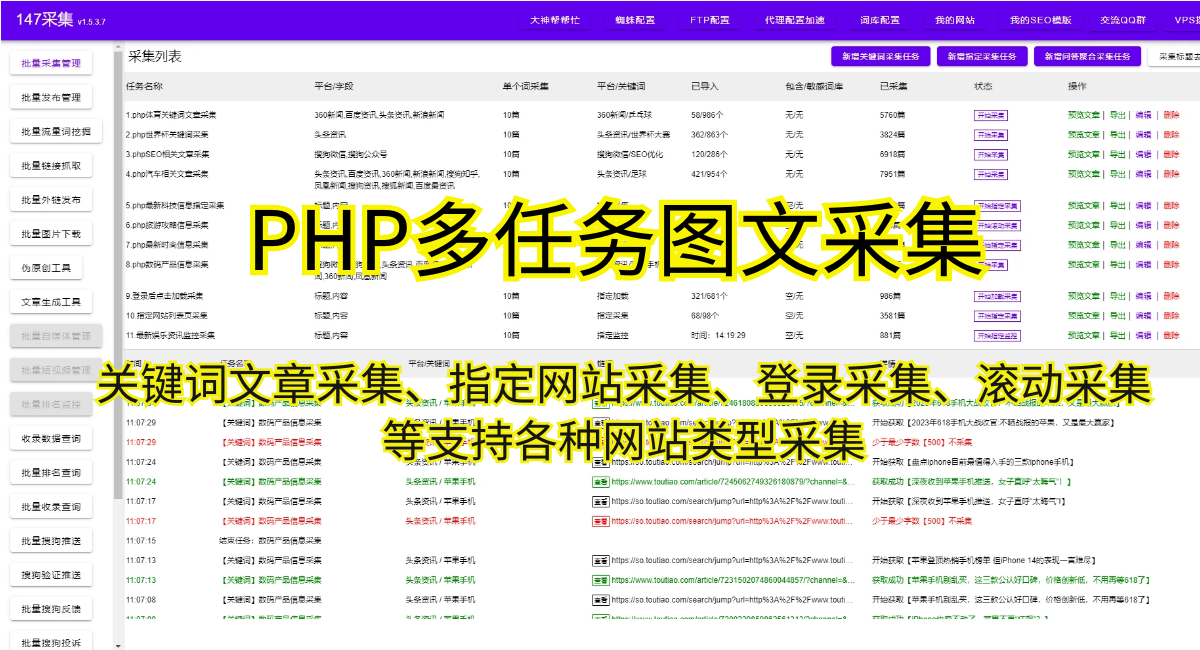
2.解析HTML代码:使用BeautifulSoup库或其他HTML解析库,解析网页的HTML代码,提取出需要的数据。
3.数据处理和存储:对获取到的数据进行处理和清洗,然后存储到数据库或者文件中,方便后续的数据分析和应用。
Python网络爬虫的实际应用
Python网络爬虫在实际应用中有着广泛的用途,下面以几个例子来说明:
1.数据采集与分析:通过爬取网页上的数据,可以进行各种数据分析和数据挖掘工作。例如,爬取电商网站的商品信息,进行价格对比和市场研究;爬取新闻网站的文章,进行热点分析和舆情监测等。
2.搜索引擎优化:通过爬虫程序获取网页的相关信息,为搜索引擎提供更准确的搜索结果。例如,爬取网页的标题、关键词和描述等信息,帮助搜索引擎正确地索引和展示网页。
3.数据监控和更新:通过爬虫程序定期监控网页上的信息,并及时更新到本地数据库。例如,爬取gupiao交易信息,及时更新gupiao行情。
总结
Python网络爬虫作为一种强大的数据采集工具,正在被越来越多的人所重视和使用。不仅可以获取互联网上的各种数据,还可以为企业决策提供更准确的信息支持。掌握Python网络爬虫的基本原理和方法,能够帮助开发者更好地从网络中采集和利用数据,提高工作效率和竞争力。
147SEO » Python网络爬虫:采集网页数据的利器



