
苹果CMS是一款功能强大的内容管理系统,它提供了丰富的内容发布和管理功能,以及灵活的模板系统。对于网站管理员来说,苹果CMS爬虫采集是快速获取和整合数据的重要手段之一。本文将介绍如何使用苹果CMS爬虫进行网站数据采集,并分享一些实用的技巧。
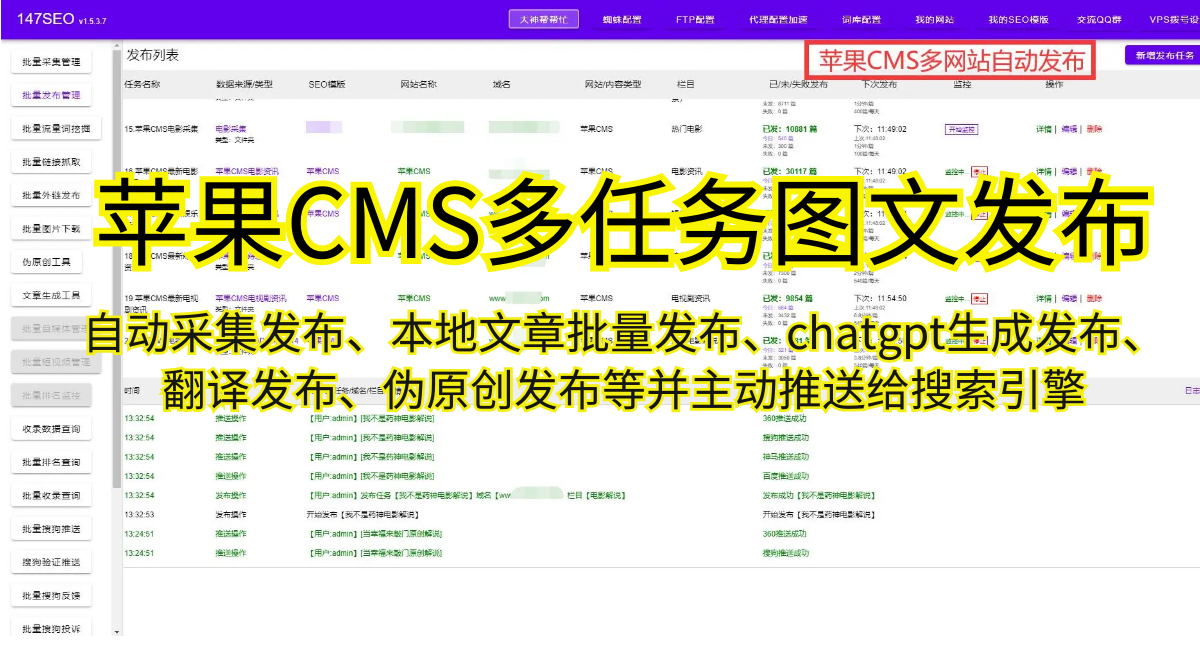
一、准备工作
在开始使用苹果CMS爬虫进行数据采集之前,需要确保已经安装了苹果CMS,并熟悉其基本操作。此外,还需要了解基本的爬虫原理和相关技术。
二、分析目标网站

在进行数据采集之前,首先需要分析目标网站的结构和数据组织方式。可以通过查看网站的HTML源代码和网页元素,了解网站的页面结构和数据存储方式。根据分析结果,确定需要采集的数据字段和对应的爬虫规则。
三、编写爬虫程序
根据目标网站的结构和数据组织方式,编写适应的爬虫程序。可以使用Python等编程语言,结合相应的爬虫框架和库,如Scrapy等,来实现数据的爬取和处理。在编写爬虫程序时,需要注意设置合适的请求头、代理IP等,以避免被目标网站的反爬虫机制拦截。
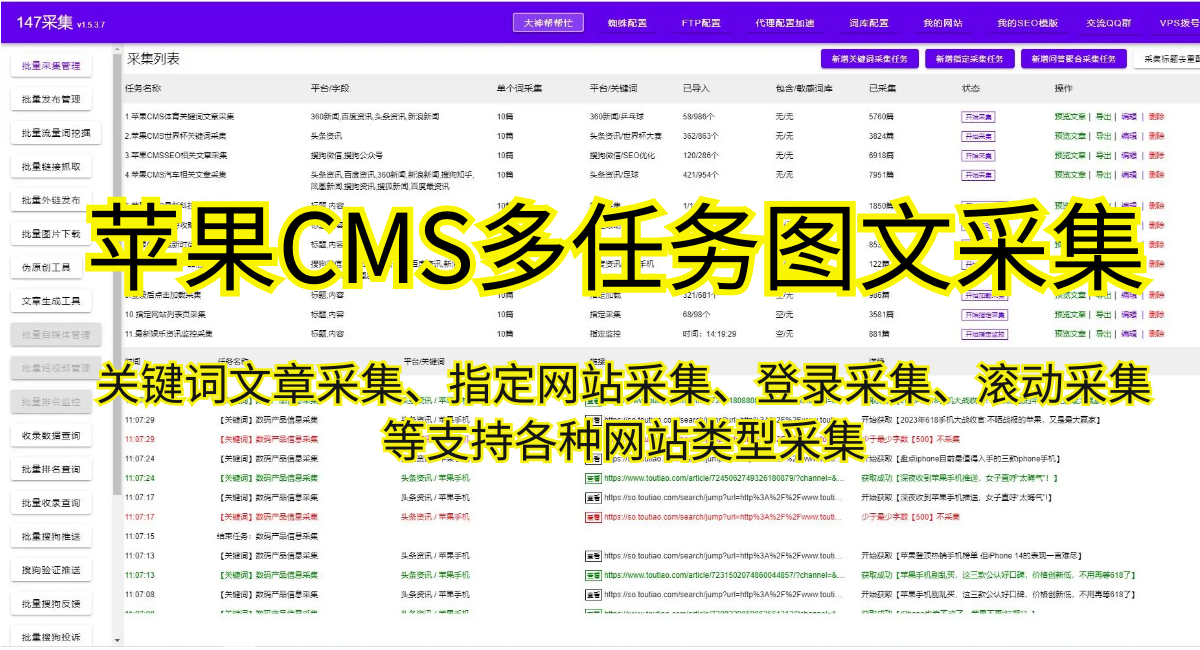
四、数据解析和存储
在数据采集过程中,需要将爬取到的数据进行解析和存储。可以使用正则表达式、XPath、BeautifulSoup等技术,根据目标网站的特点和需求,提取所需的数据字段。然后,将数据存储到数据库或文件中,以便后续的数据处理和展示。
五、数据清洗和去重

采集到的数据可能存在重复、不完整或错误的情况,需要进行清洗和去重处理。可以通过编写相应的数据处理脚本,对数据进行去重、格式化、筛选等操作,以保证数据的质量和准确性。
六、定时采集和自动化
若需要定期获取目标网站的数据,可以设置定时任务,自动执行爬虫程序。可以使用系统自带的定时任务功能,或结合第三方工具,如crontab、Task Scheduler等,实现定时采集和数据更新。
七、注意事项
在进行爬虫采集时,需要遵守相关规则法规和网站的使用规定,尊重网站的权益和隐私。同时,需注意数据采集的频率、速度和并发量,避免对目标网站造成过大的压力和影响。
八、总结
苹果CMS爬虫采集是一项常用且有效的数据获取方法,可以广泛应用于网站数据整合、业务分析等领域。通过本文的介绍,相信读者已经对苹果CMS爬虫采集有了初步的了解,并可以根据实际需求,灵活运用和扩展相关技术,提升数据采集的效率和质量。
147SEO » 苹果CMS爬虫采集教程



