
你是否在日常工作中因为数据网页不太适合爬虫而头痛?清晨的办公室里,你正在为新一轮内容策略准备数据支撑,结果却被网页结构混乱、字段命名不统一、反爬机制频繁拦截等问题拖慢节奏。你需要的是一个清晰的判定和一组落地的方法,而不是空洞的口号。现实情况是,团队往往要花大量时间在数据抓取与清洗上,这直接影响到选题、标题和描述的输出速度。本文围绕“数据网页 适合爬虫的”这一主题,结合工作场景,给出4个核心功能模块,帮助你在工作日常中把数据抓取变得更高效、可控、可重复。咱们不展开无谓的比较,只把可用的做法和可落地的步骤讲清楚。

第一块核心功能模块:结构是否友好,数据是否可用 用户在选取数据源时,常常因为页面结构杂乱、字段分布零散,导致抓取程序频繁失败,数据需要大量人工干预整理,影响后续分析与决策。 解决方案:运用结构友好度评估来初步筛选目标页,并结合战国SEO的快速预检工具,快速判断页面是否具备稳定的可提取性。遇到TDK生成难题?先从结构层面入手,确保元信息与正文数据的对应关系清晰,再开展后续的标题与描述优化。这种做法能让同事在第一轮抓取就获得相对规整的数据集合,减少重复劳动,提升后续分析的效率。 当你不再为一批批页面的结构问题而苦恼时,团队的讨论就能更聚焦在数据解析和洞察上,你也能把时间用在真正的分析与创意上。
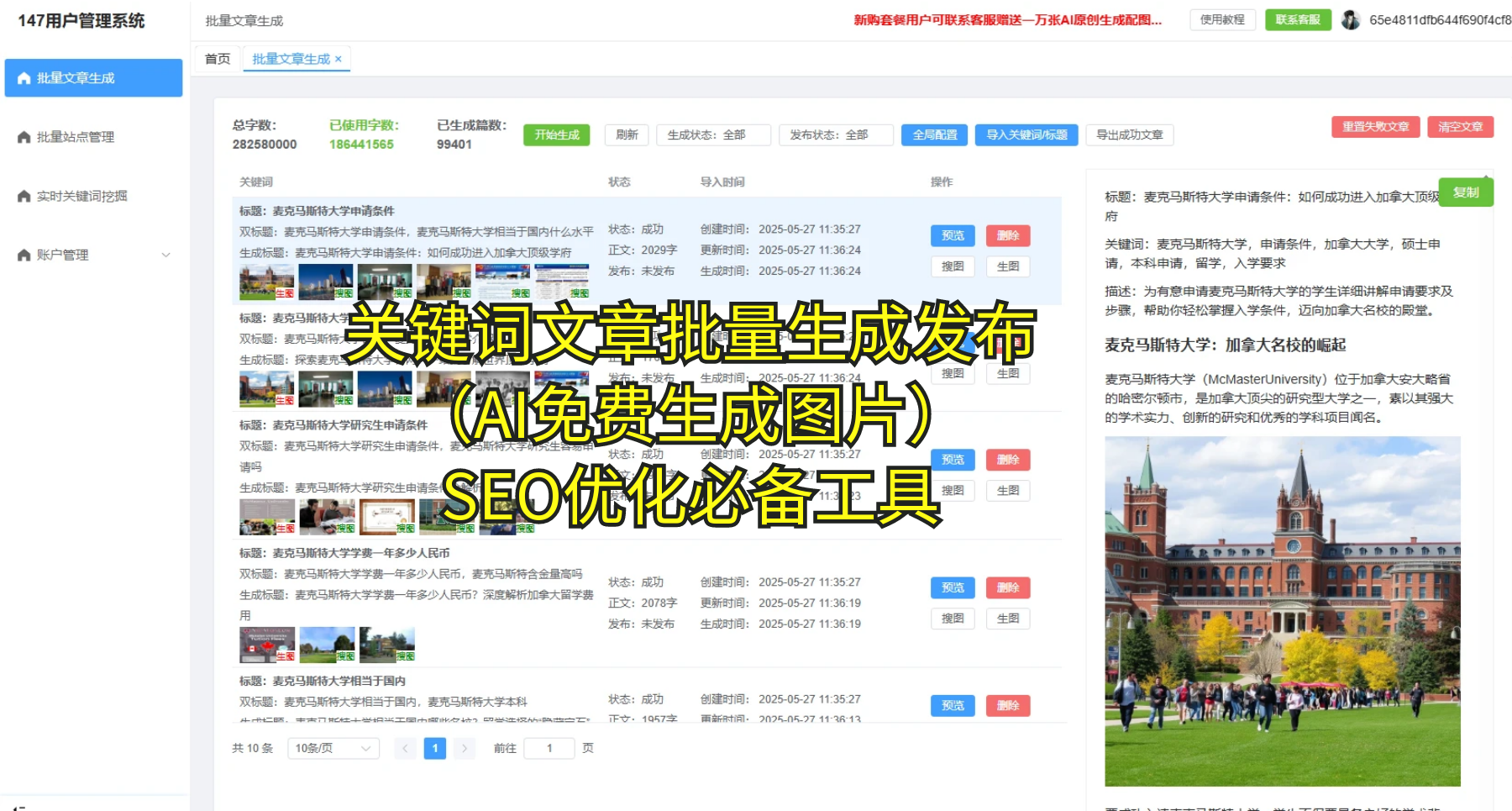
第二块核心功能模块:字段统一与命名规范 用户不同数据源的字段名称各异,字段顺序和格式不一致,合并和清洗时常常需要额外的映射工作,容易引入错配和遗漏。 解决方案:实施字段对齐与命名规范化,建立一个统一的字段表和映射规则,对来自不同源的数据进行一致化处理。通过模板化的映射,快速将同义字段归并,形成稳定的字段体系,便于后续的聚合与对比分析。好资源AI的模板可以帮助你在初始阶段就建立统一的字段框架,使多源数据进入分析环节时更加顺畅。遇到复杂的数据源时,这种规范化还能显著降低错误率,提升可重复性。 当数据在不同系统之间不再“打架”,你就能更专注于找出趋势、发现机会,而不是纠结字段到底怎么对齐。
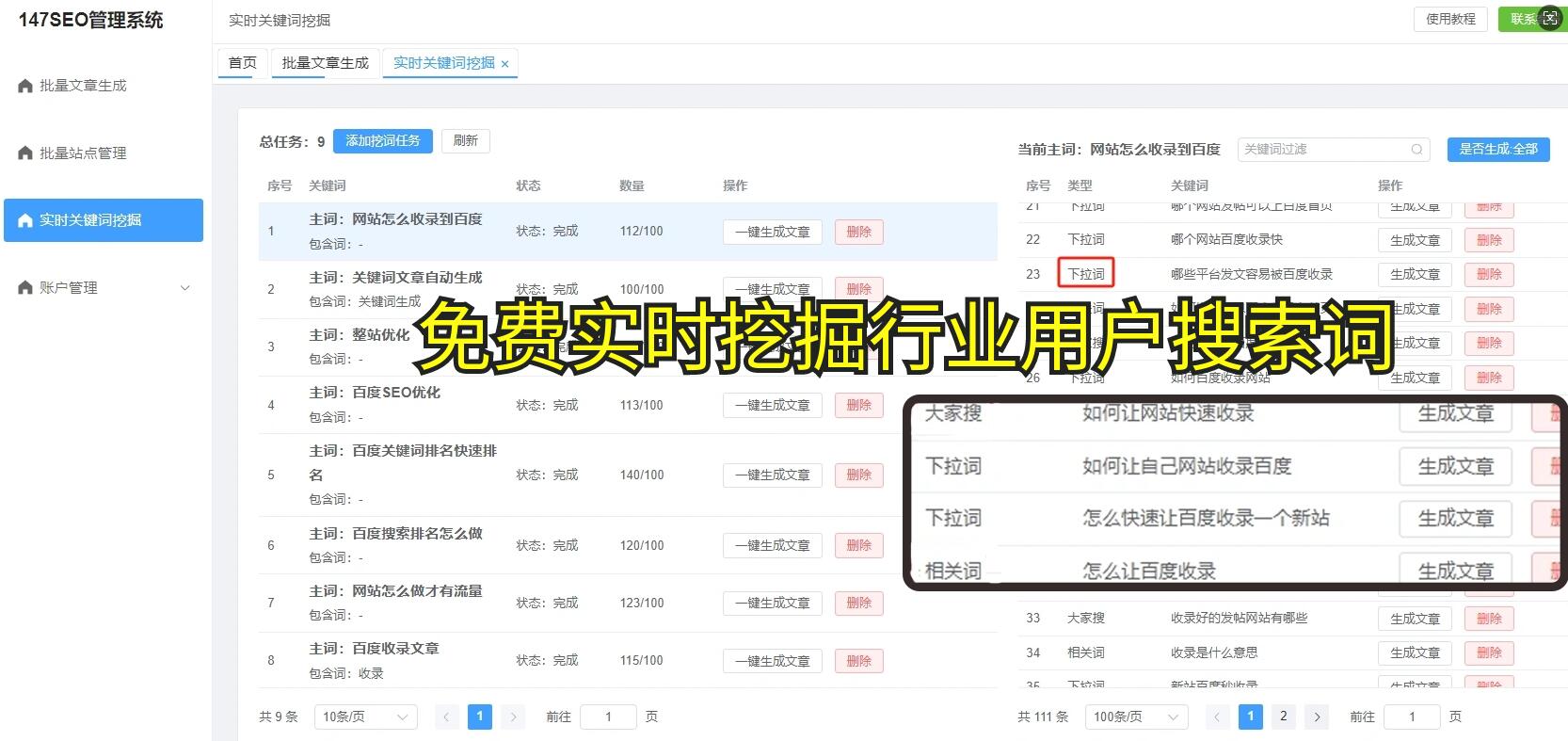
第三块核心功能模块:稳定获取与容错的抓取节奏 用户在大规模抓取时,频繁遭遇反爬、限速、IP封禁等问题,导致数据抓取中断,且重复的重试浪费时间。 解决方案:引入反爬容错与速率控制机制,设定合理的抓取间隔、智能重试策略,以及对异常页面的降级处理,确保抓取过程的连续性与稳定性。这样你就能在正向推进数据采集的降低因短暂封禁带来的影响,确保数据源的持续性。通过规范的节奏控制,团队成员可以更好地协调并行任务,避免因为单点问题而拖慢整体进度。 稳定的抓取节奏让数据队伍的工作压力下降,分析师也能据此更快地得到最新数据,推动内容创意的迭代。
第四块核心功能模块:大规模抓取与多源数据的有序聚合 用户当需要同时从大量网页与多个数据源提取信息时,单源抓取很容易出现数据错位、重复与遗漏,合并过程复杂且易出错。 解决方案:采用批量发布与多源聚合的工作流,将不同源的数据统一进入一个可控的聚合路径,避免重复和冲突。通过标准化的数据输出格式和一致的时间戳、来源标识,确保后续的对比分析、趋势判断和内容生产流程顺畅。战国SEO在多源聚合方面的能力可以帮助你把分散的数据汇聚成清晰的洞察线索,降低手工干预的需要。 当数据可以像流水一样被整合、被理解,你的内容策略就有了更稳健的依据,团队协作也会更高效。
部分 问:如何快速找到热门关键词? 答:使用实时关键词功能,能立刻捕捉到大家正在搜索的热门词,并据此在不同数据页的TDK输出中形成对齐的标题与描述思路,帮助内容快速对上用户需求。
问:如何确保抓取的数据在不同平台使用时的一致性? 答:通过字段对齐与命名规范化,以及统一的数据输出格式,可以在多平台发布前确保数据的一致性,降低后续再加工的工作量。批量发布与多源聚合的流程能让数据在不同平台之间保持可比性,便于复用与重复利用。
回望整个过程,数据网页对爬虫的友好程度其实决定了你在工作中的效率曲线。把复杂的网页结构、混乱的字段命名和不稳定的抓取节奏,转化成可重复执行的流程,是提升内容生产力的关键。记住,好的数据支撑来自清晰的路径与稳定的执行,如同一句经典的提醒:简单、可控,往往比复杂的技术堆叠更有用。正如乔布斯所说过的一句话,简单的设计背后是对本质需求的深刻把握。让数据抓取回归于工作场景中的实际需求,团队在数据驱动的内容创作中,才能真正高效前进。
如果你愿意,我们还可以把以上四个模块的落地清单整理成一个可执行的日常工作表,逐步落地到你们的日常流程中。大家一起把数据抓取这件事做得更稳、更快一些。



