
在互联网时代,数据是非常宝贵的资产,许多企业和个人都希望保护自己的数据免受爬虫的攻击。爬虫可以用于获取大量数据,包括个人隐私和商业机密等敏感信息。为了保护数据的安全性,我们需要采取一些措施来防止爬虫爬取数据。
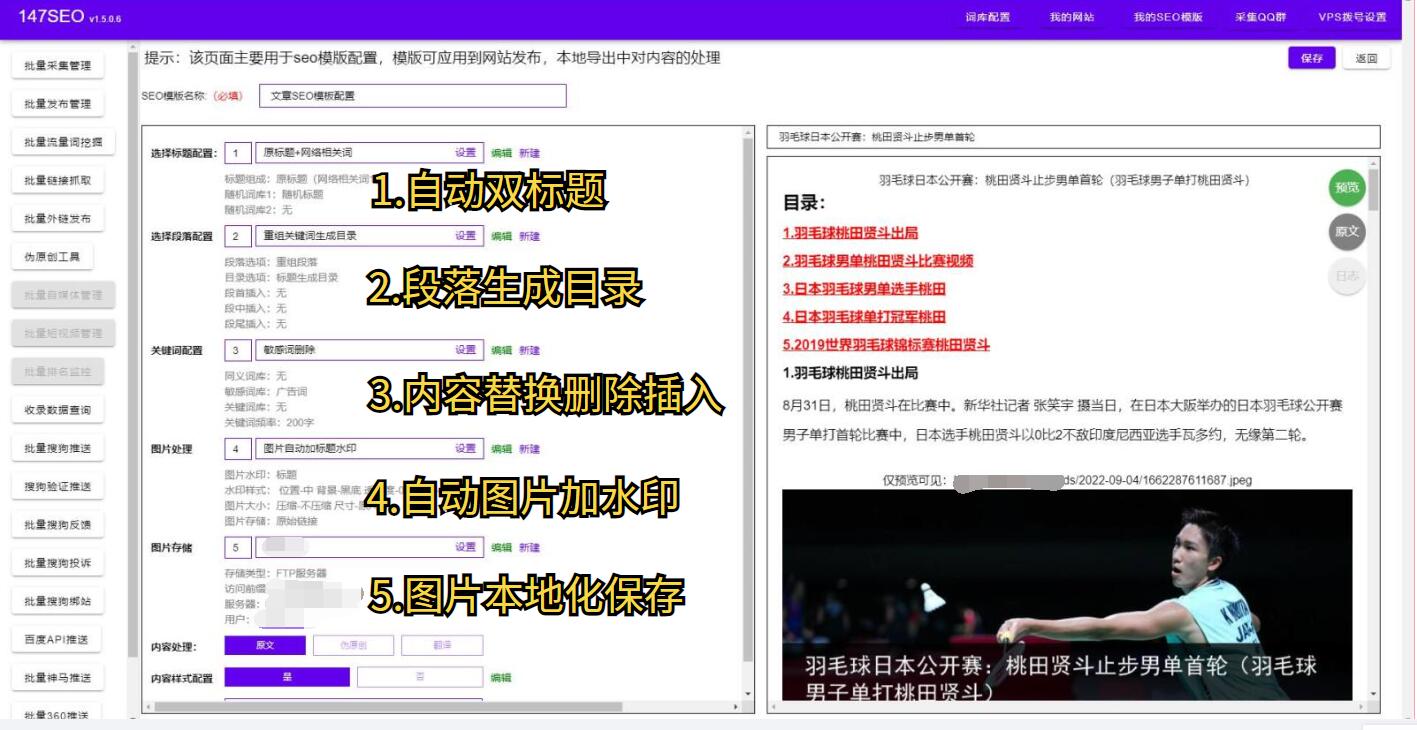
一、使用反爬虫技术 反爬虫技术是最常用的防止爬虫爬取数据的方法之一。通过在网站中引入验证码、密码、动态页面等措施,可以有效地阻止大部分爬虫的访问。此外,还可以使用User-Agent验证、IP封禁、限制访问频率等技术手段来防止恶意爬取。
二、数据加密和隐藏 为了防止爬虫直接获取数据,我们可以对敏感数据进行加密和隐藏。例如,可以对敏感字段进行加密存储,只在需要使用时才进行SEO。同时,还可以通过异步加载数据、使用图片代替文本等方式来隐藏数据,增加爬虫的难度。
三、使用动态生成的内容 爬虫通常会根据网页的结构和规律进行数据抓取。为了防止爬虫轻易地获取数据,我们可以使用动态生成内容的方法。例如,可以使用JavaScript动态生成部分数据,或者通过Ajax等技术来加载数据,增加爬虫的难度。
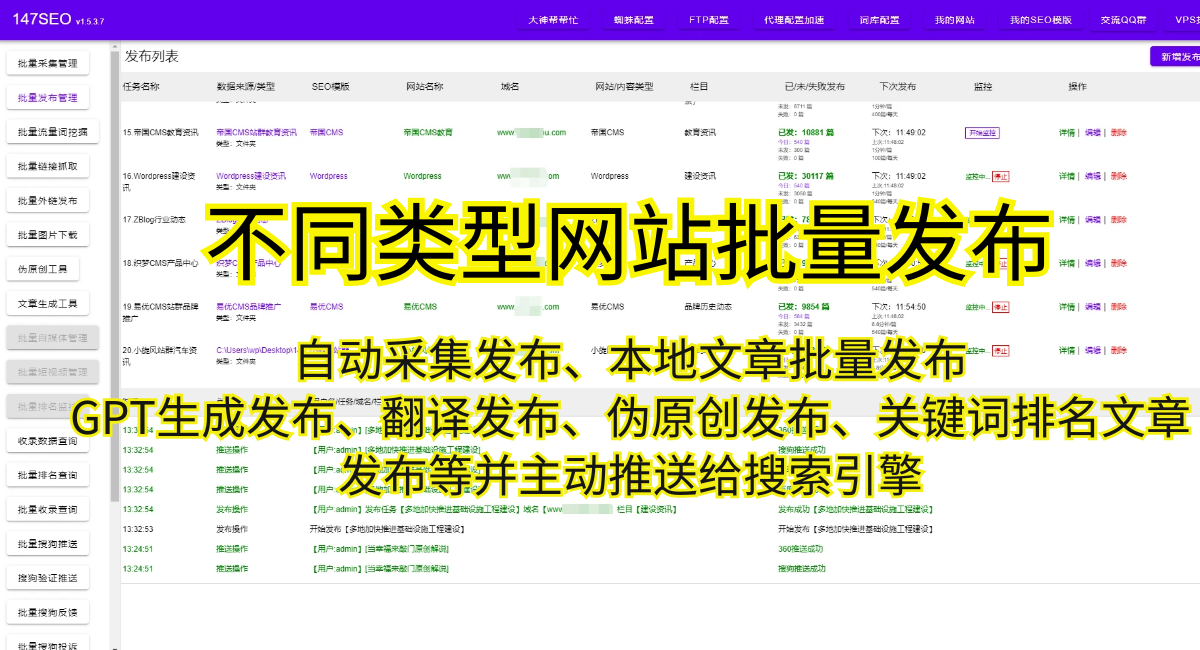
四、定期更新网站结构 爬虫通常依赖于网页的结构和规律进行数据抓取。为了应对不断变化的爬虫技术,我们应定期更新网站的结构和布局。通过修改HTML标签、CSS样式或者增加删除一些元素,可以有效地防止爬虫的攻击。
五、监控和分析爬虫行为 及时发现和分析爬虫的行为对于保护数据至关重要。通过监控网站的访问日志、使用网络流量分析工具等,我们可以了解爬虫的来源、访问频率和抓取的数据等信息。这些信息可以帮助我们识别和阻止恶意爬虫。
六、使用专业的爬虫防护工具 如果您的网站需要高级的爬虫防护技术,可以考虑使用专业的爬虫防护工具。这些工具通常具备强大的反爬虫能力,可以根据不同的情况自动调整策略,提高防护效果。
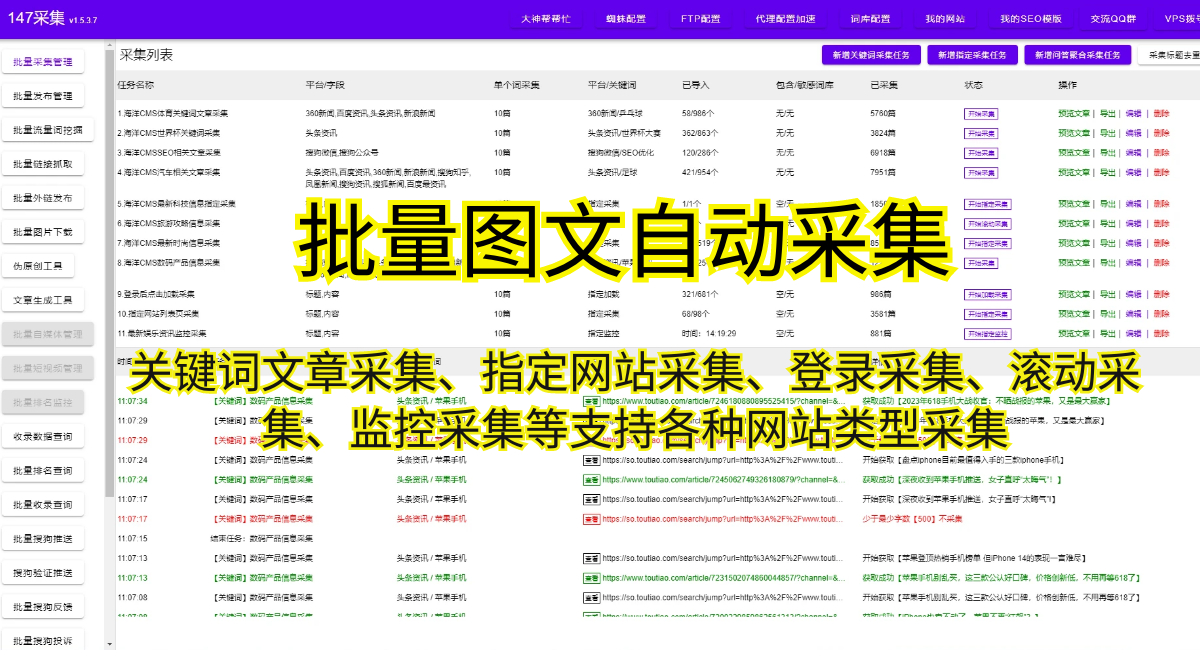
总之,防止爬虫爬取数据是一个持续的挑战。通过采取合适的技术和策略,我们可以保护数据的安全性,减少爬虫的攻击。希望这些方法和建议能够帮助您有效地防止爬虫爬取数据,保护自己的利益。



