
在当今信息爆炸的时代,网站数据成为了企业和个人获取价值的重要来源。而要获取准确、全面的数据就需要大量的时间和人力投入,这无疑给数据分析师和营销人员带来了巨大的负担。那么如何利用爬虫技术提升网站数据收集效率呢?
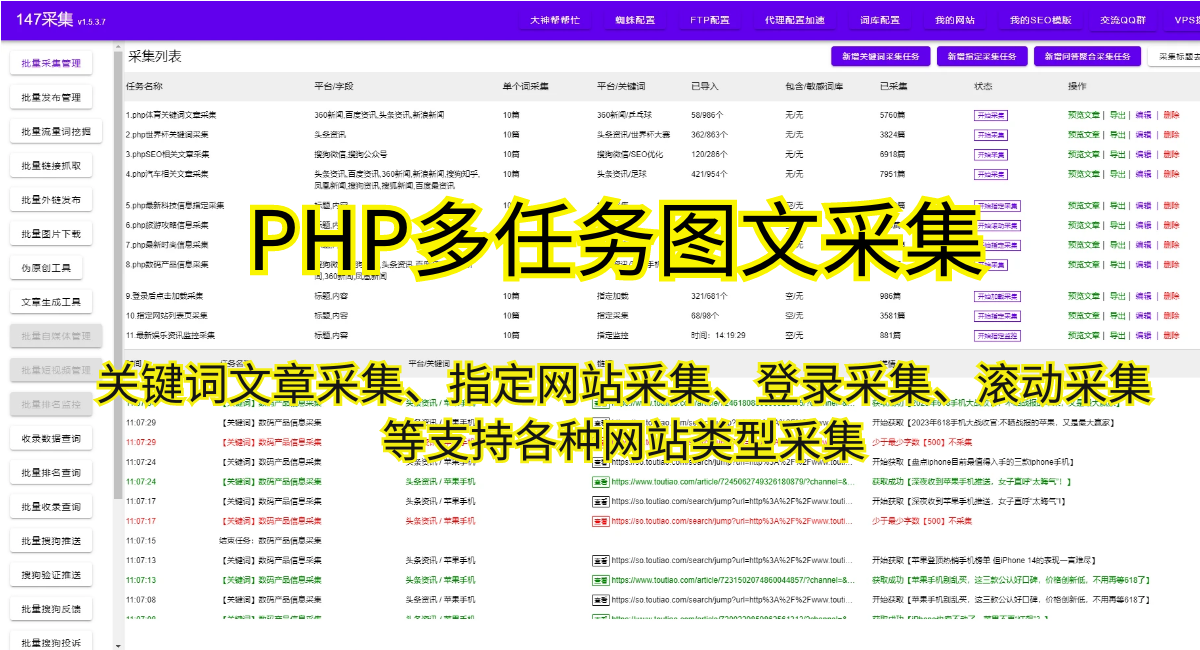
爬虫技术,顾名思义,即通过编写程序模拟人类浏览行为,自动获取网页上的数据。它可以快速地爬取互联网上的大量数据,并进行结构化处理,极大地提高了数据收集效率。下面,我们将以一个实际案例,介绍如何利用爬虫技术爬取一个网站的数据。
首先,我们需要选择合适的爬虫工具。市面上有很多爬虫工具可供选择,例如Python的Scrapy框架、Node.js的Puppeteer等。根据实际需求和技术储备,选择合适的工具非常重要。
接下来,我们需要了解目标网站的结构和数据特点,这样才能更好地编写爬虫程序。通常可以通过查看网页源码、分析API接口、使用开发者工具等方法来获取相关信息。这些信息包括网页的URL结构、数据所在节点的唯一标识、数据格式等等。
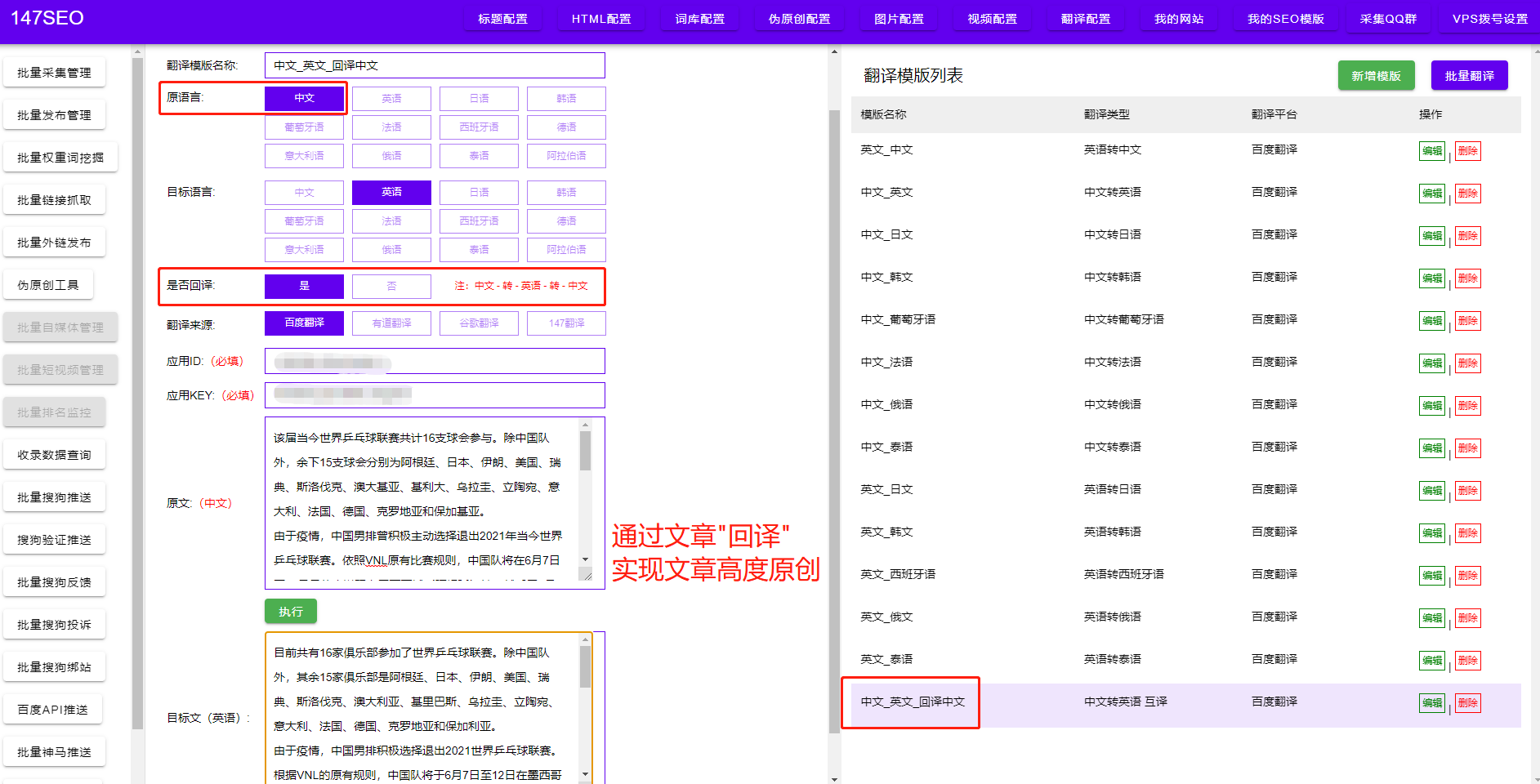
一旦我们了解了目标网站的结构,就可以开始编写爬虫程序了。首先,我们需要发送HTTP请求,获取网页的HTML代码。然后,通过使用XPath、CSS选择器等方式,定位到目标数据所在的节点,并提取出需要的数据。最后,我们可以将提取到的数据保存到本地文件或数据库中,以备后续分析和使用。
当爬虫程序编写完成后,我们需要进行测试和调试。通过模拟多种情况下的爬取操作,确保程序能够稳定运行并正确提取数据。同时,我们需要遵守网站的爬虫规则,不要给目标网站造成过大的访问负担,避免触发反爬虫机制。
除了基本的爬虫技术外,还可以利用一些高级技巧来提升数据收集的效率。例如,使用多线程或异步请求来并发地获取数据,减少爬取时间;使用代理服务器来隐藏自己的真实IP地址,防止被封禁;使用反反爬虫技术来绕过一些常见的反爬虫手段等等。当然,这些技巧需要根据具体情况来选择和使用。
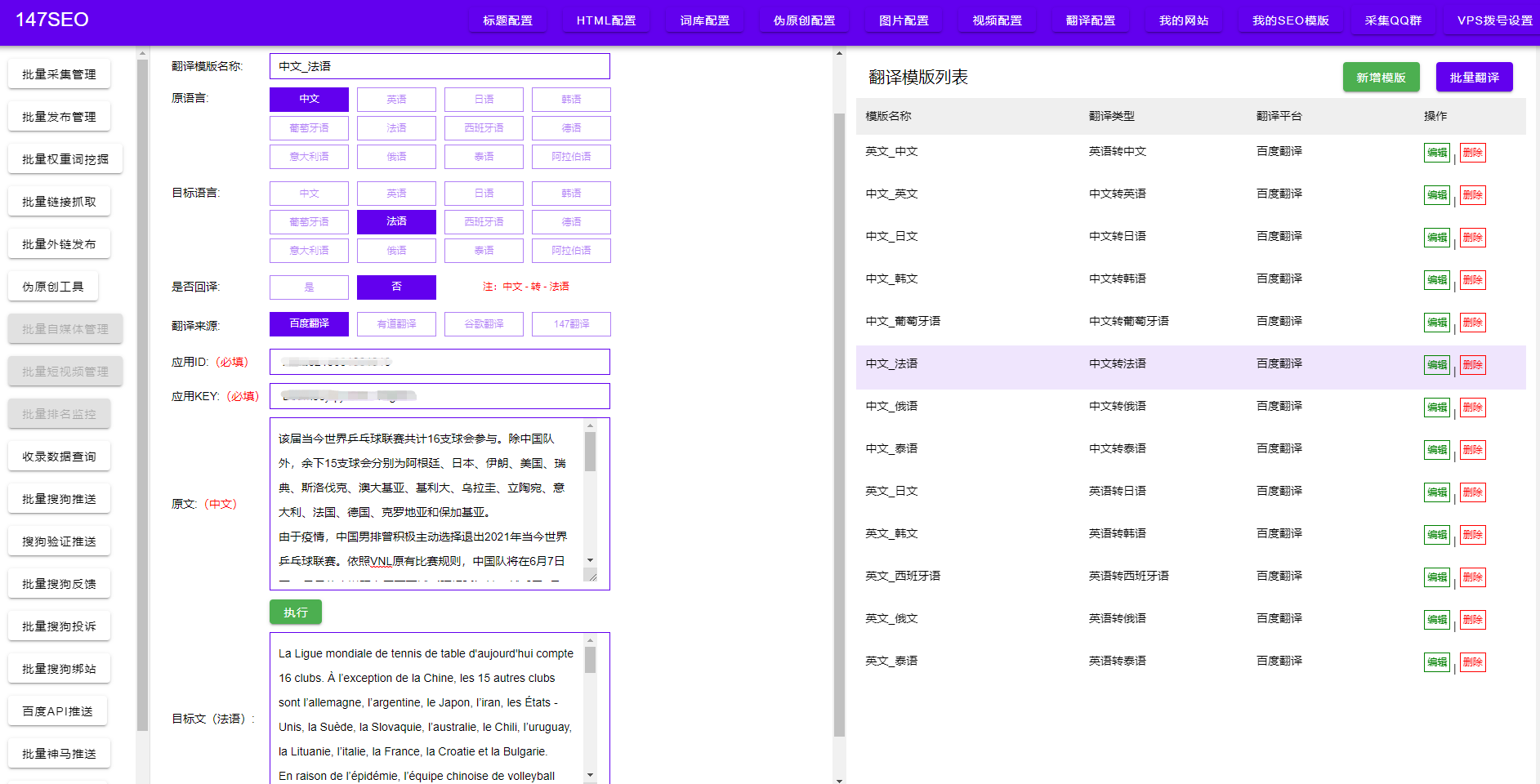
总之,利用爬虫技术可以大大提升网站数据收集的效率和准确性。但是,我们在使用爬虫技术时也要遵守相关的规则法规和道德规范,不要滥用数据和侵犯他人的权益。只有正确合法地使用爬虫技术,才能充分发挥其价值,为企业和个人带来更多的益处。



