
现代企业对于信息的获取和处理变得日益重要。随着互联网的快速发展,网站抓取技术成为一种有力的工具,能够实现对互联网上海量数据的快速采集和分析。本文将介绍网站抓取的基本概念、应用场景以及使用网站抓取实现信息采集与数据分析的方法。
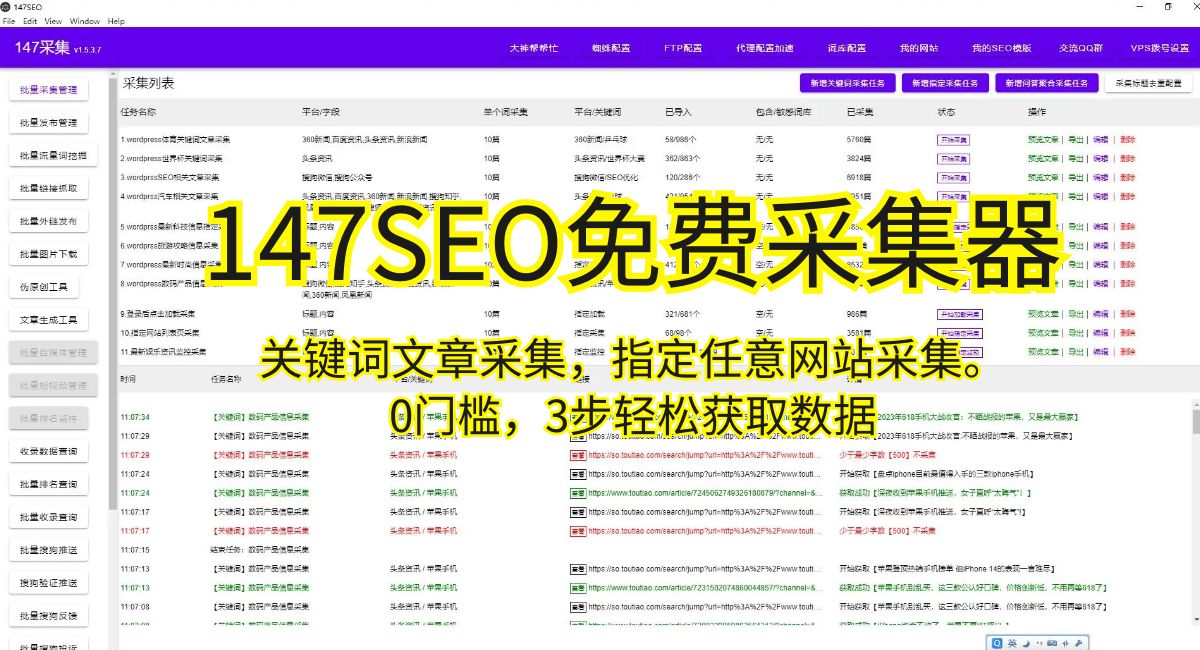
网站抓取,是指通过编写程序模拟浏览器的行为,访问特定的网页,获取所需的数据并进行处理的过程。它可以自动化地遍历链接,采集大量信息,从而将海量数据转化为有用的知识。网站抓取技术可以应用于多个领域,如舆情监测、竞争情报分析、商品价格比较等。通过对抓取的数据进行分析,企业可以获取市场动态、竞争对手的信息,做出更加明智的决策。
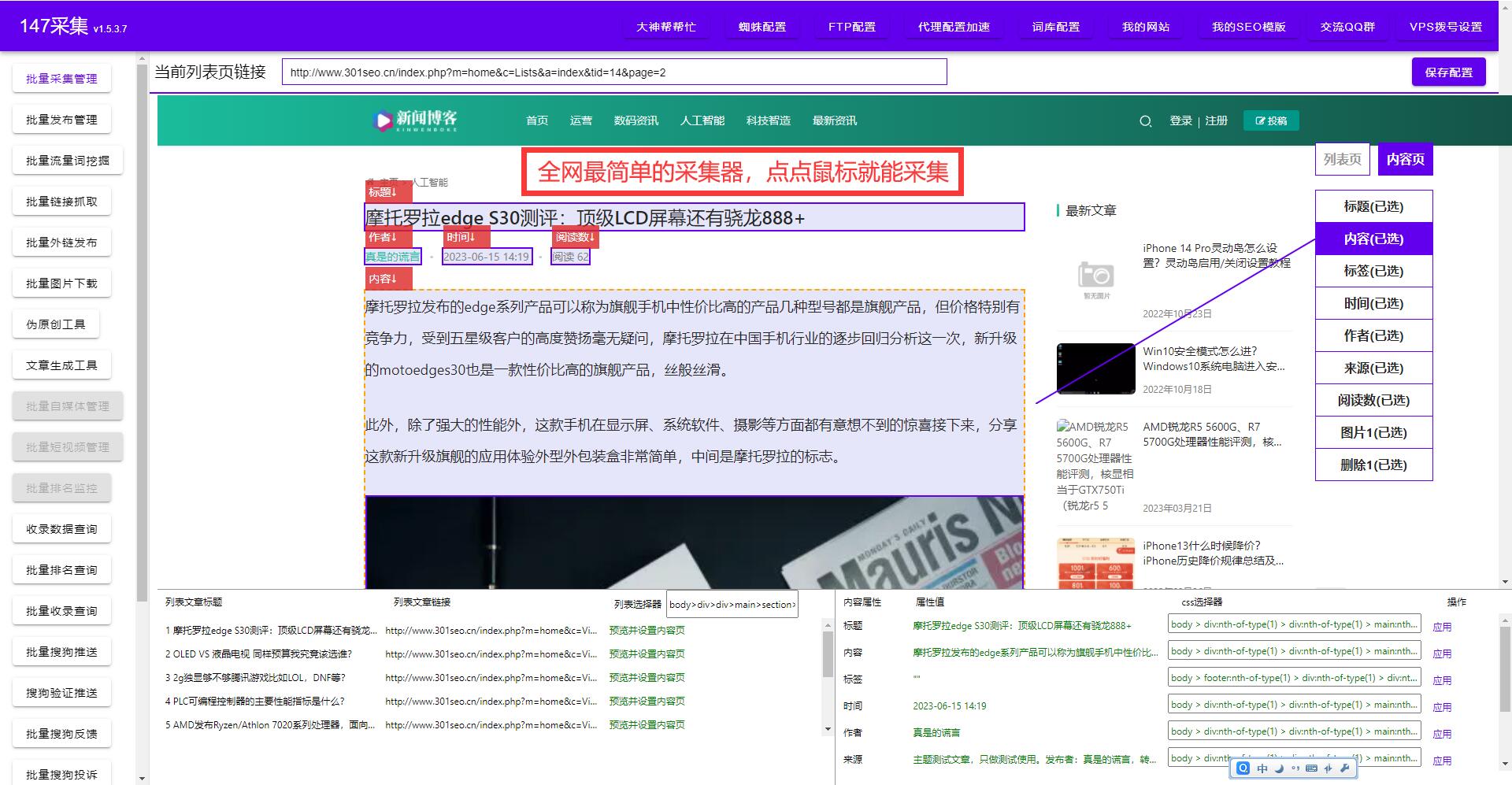
要使用网站抓取实现信息采集与数据分析,首先需要确定要抓取的网站和关键信息。然后,选择合适的抓取工具和编程语言进行开发。常见的抓取工具包括Python的Scrapy、Java的Jsoup等。在开发过程中,需要注意处理反爬机制,以保证数据的完整性和准确性。
抓取数据后,下一步就是对数据进行处理和分析。可以使用各种数据分析工具,如Excel、Python的Pandas库、R语言等。通过对数据进行清洗、筛选和统计,可以得到有用的结论和洞察。比如,在舆情监测中,可以通过抓取社交媒体上的用户评论来了解消费者对某个品牌或产品的态度,以及竞争对手的市场表现等。
网站抓取技术的应用还有很多局限性和挑战。首先,合法合规的问题。在进行网站抓取时,需要遵守规则法规和网站的使用协议,不得侵犯他人的合法权益。另外,网站抓取也面临着反爬机制的挑战。为了防止被抓取,网站可能会设置IP限制、验证码等,需要开发者做出相应的应对措施。
综上所述,网站抓取是一种实现信息采集与数据分析的重要技术。通过使用网站抓取,企业可以快速获取海量的数据,并通过数据分析得出有用的结论,为决策提供支持。然而,网站抓取也面临着合法合规和反爬机制的挑战,需要开发者高度关注。相信随着技术的不断发展和完善,网站抓取技术将在更多领域得到广泛应用。



