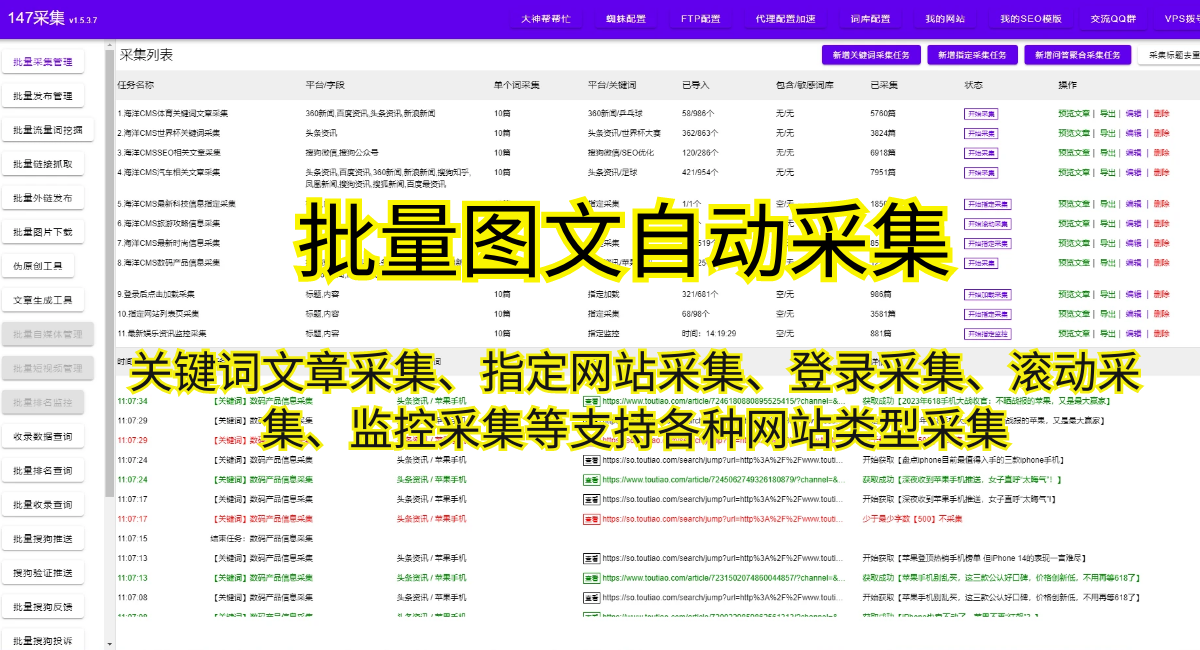
在信息爆炸的时代,随处可见大量有价值的网页信息。然而,面对如此庞大的数据量,如何高效地提取需要的信息成为了一个难题。幸运的是,网页信息抓取技术的出现,为我们解决了这个难题。
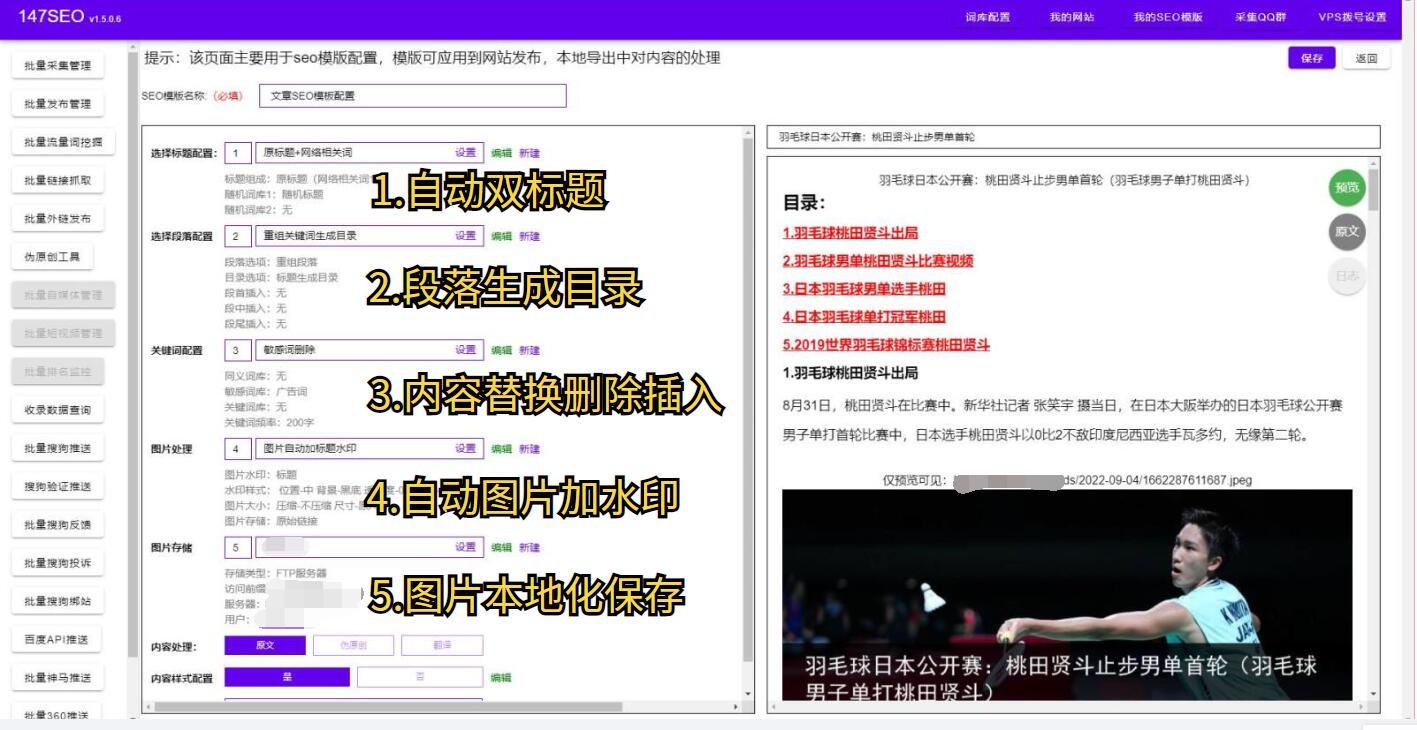
网页信息抓取,顾名思义,就是通过自动化程序实时获取互联网上的网页数据。它可以将通常需要人为复制粘贴的数据转化为结构化数据,大大节省了人力ZY,提升了工作效率。
要实现网页信息抓取,我们需要使用一些专业的工具和技术,如编程语言Python、JavaScript、HTML、CSS,以及相关的库和框架。通过这些工具和技术,我们可以编写爬虫程序,模拟人类浏览器行为,解析网页结构,提取我们需要的数据。
网页信息抓取技术的应用场景非常广泛。比如,在电子商务领域,我们可以通过抓取网页信息,实时监测竞争对手的产品价格,帮助我们制定更有竞争力的价格策略;在金融领域,我们可以抓取各种caijing新闻,帮助分析师更快地掌握市场动态;在舆情监测方面,我们可以抓取社交媒体上的评论和观点,了解用户的真实反馈。
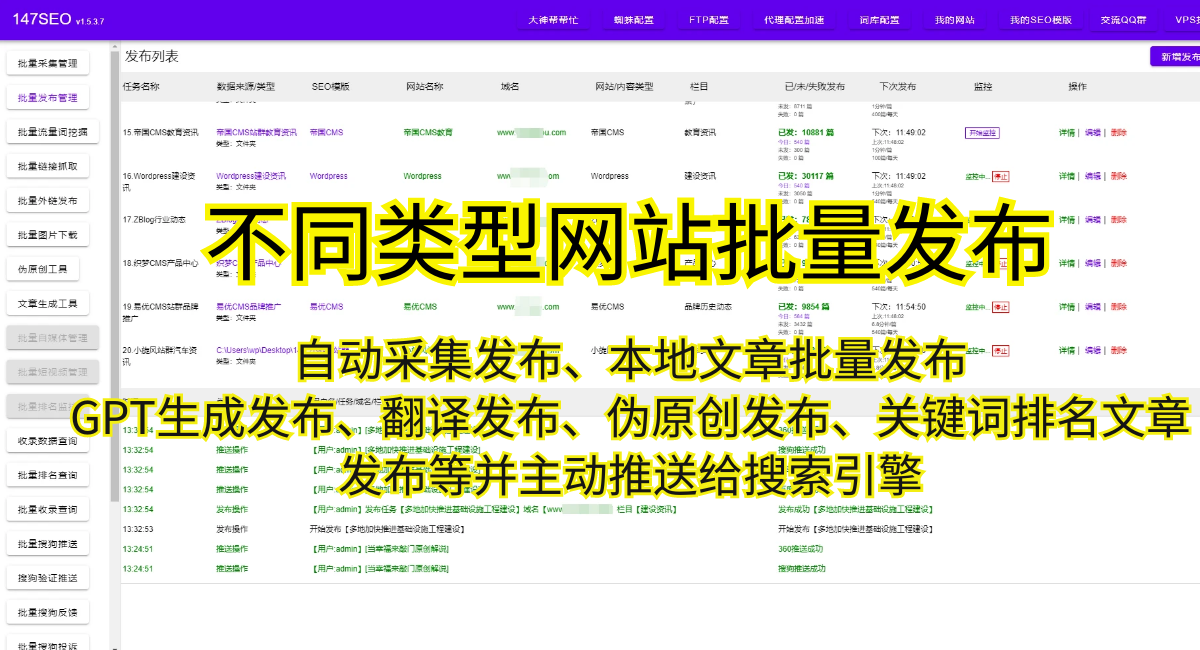
网页信息抓取技术不仅可以帮助我们获取信息,还可以进行大数据分析和挖掘。通过分析抓取到的大量网页数据,我们可以发现用户行为规律,提供个性化服务;也可以挖掘潜在商机,辅助决策者制定发展战略。
然而,网页信息抓取也面临一些挑战。首先,网站的反爬虫机制可能会限制我们的抓取行为,需要我们采取相应的反反爬虫策略。其次,网页结构的变动可能会导致我们的抓取程序失效,需要我们不断维护和优化。另外,抓取大量数据可能会给网站带来访问压力,需要合理控制抓取频率,遵守网络道德与规则法规。
综上所述,网页信息抓取是挖掘互联网宝藏的利器。通过合理利用网页信息抓取技术,我们可以轻松获取所需数据,对大数据进行分析和挖掘,不仅提高了工作效率,还帮助我们做出更明智的决策。但同时,我们也需注意合规和道德,遵守相关规则法规,保护用户隐私。抓取互联网宝藏,让我们从中受益的同时,也要尊重和维护互联网的生态。