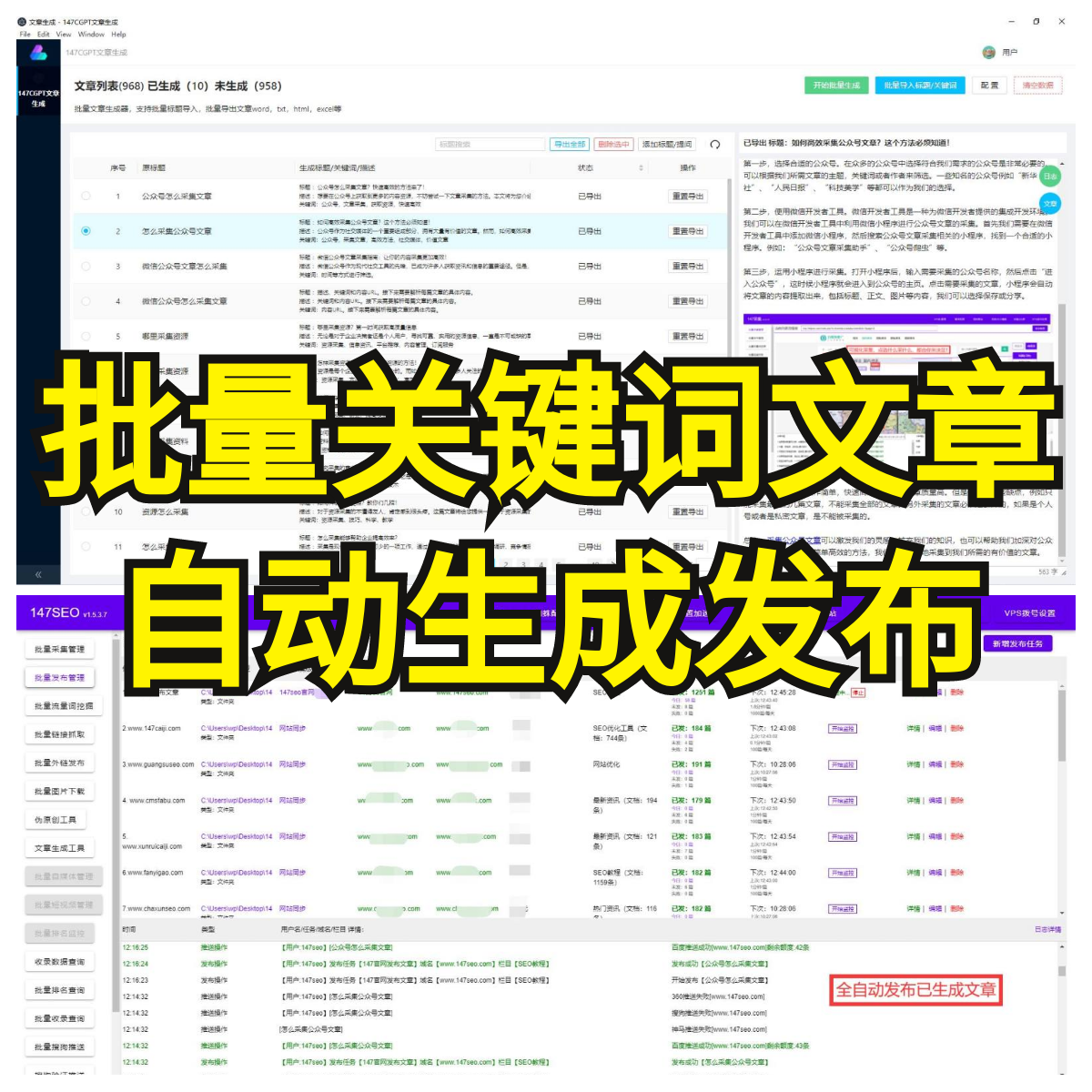
在当前大数据时代,收集和分析数据对于企业和个人来说变得越来越重要。而构建一个高效的数据处理和分析环境则是必不可少的一步。WPS作为一款强大的办公软件,为用户提供多种数据处理和分析的功能,然而,手动从互联网上获取数据并导入到WPS中是一项耗时且繁琐的工作。因此,本文将向您介绍如何使用爬虫技术来优雅地将网页数据导入到WPS,让您更高效地处理和分析数据。
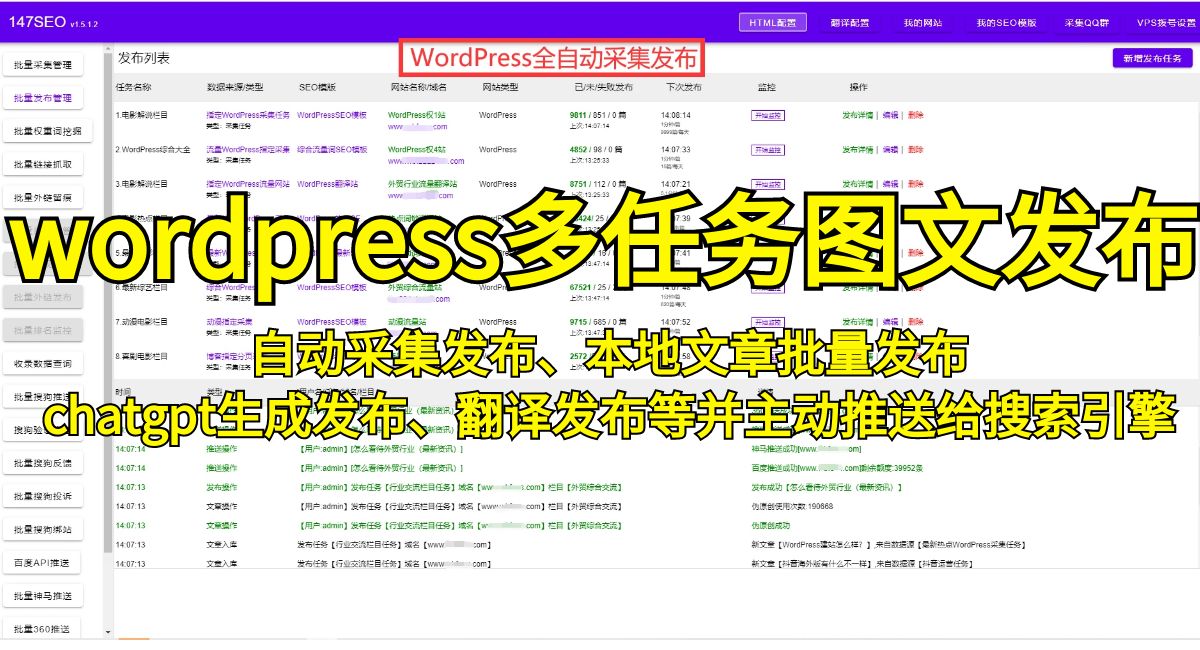
首先,我们需要准备一个爬虫工具。Python是一个功能强大且易于使用的编程语言,同时也有许多强大的爬虫框架可以使用。我们可以选择使用Scrapy,一个Python编写的开源爬虫框架,它简化了爬取网页数据的过程,并提供了丰富的功能和扩展性。
接下来,我们需要确定要爬取的网页。可以选择一些公开的数据源网站,如政府机构、大学、企业的数据门户网站等。这些网站通常提供了结构化的数据,比如CSV、Excel等格式,这将使得我们导入到WPS中更加方便。
启动Scrapy,首先我们需要定义要爬取数据的目标网址和需要提取的数据字段。在Scrapy的配置文件中,可以指定爬虫的URL以及需要提取的字段,如标题、日期、正文等。这样Scrapy会自动爬取目标网站的数据,并将它们储存在一个临时的数据文件中。
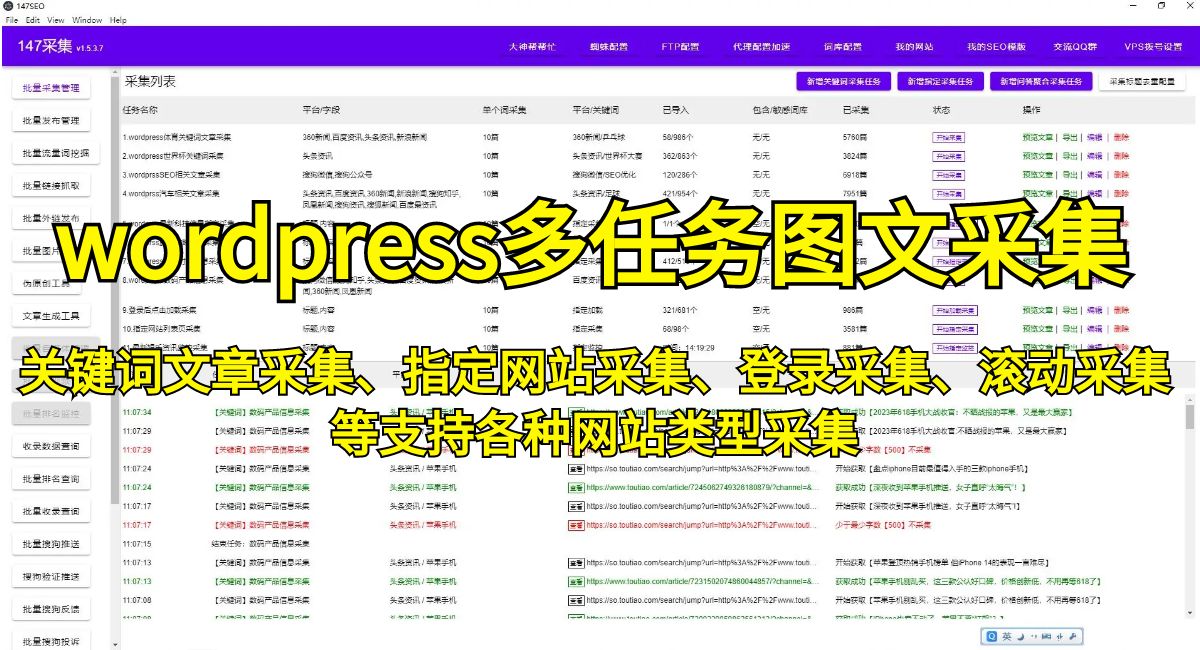
在爬虫需要进行数据清洗和处理的时候,可以使用BeautifulSoup等HTML解析库提取关键数据。这些库可以帮助我们解析网页的HTML结构,并提取需要的数据字段。同时,我们还可以使用正则表达式来进行数据的进一步清洗和规范化。
当爬虫完成数据的爬取和清洗后,我们就可以将数据导入到WPS中进行进一步的处理和分析了。WPS支持多种数据文件格式,如CSV、Excel等。我们可以选择合适的格式将数据保存为文件,然后利用WPS提供的数据处理和分析功能进行进一步的操作。
总结起来,使用爬虫技术将网页数据导入到WPS是一项非常有效的数据处理和分析方法。通过编写爬虫程序,我们可以优雅地自动化获取数据,并将其导入到WPS中进行进一步的处理和分析。这样不仅节省了大量的时间和人力成本,也提高了数据的准确性和可靠性。希望本文能够对您在数据处理和分析方面提供帮助,使您的工作更加高效和优雅。