
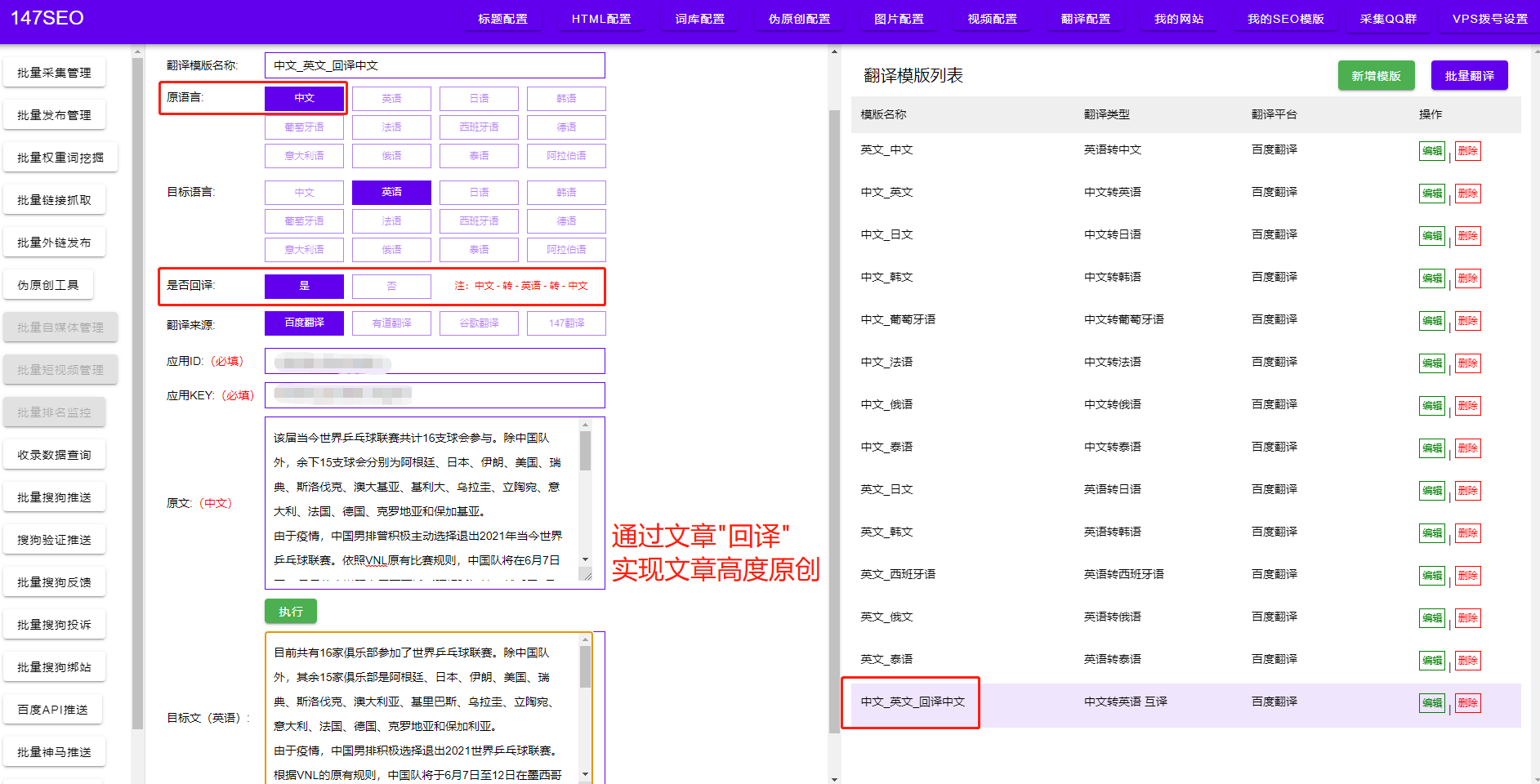
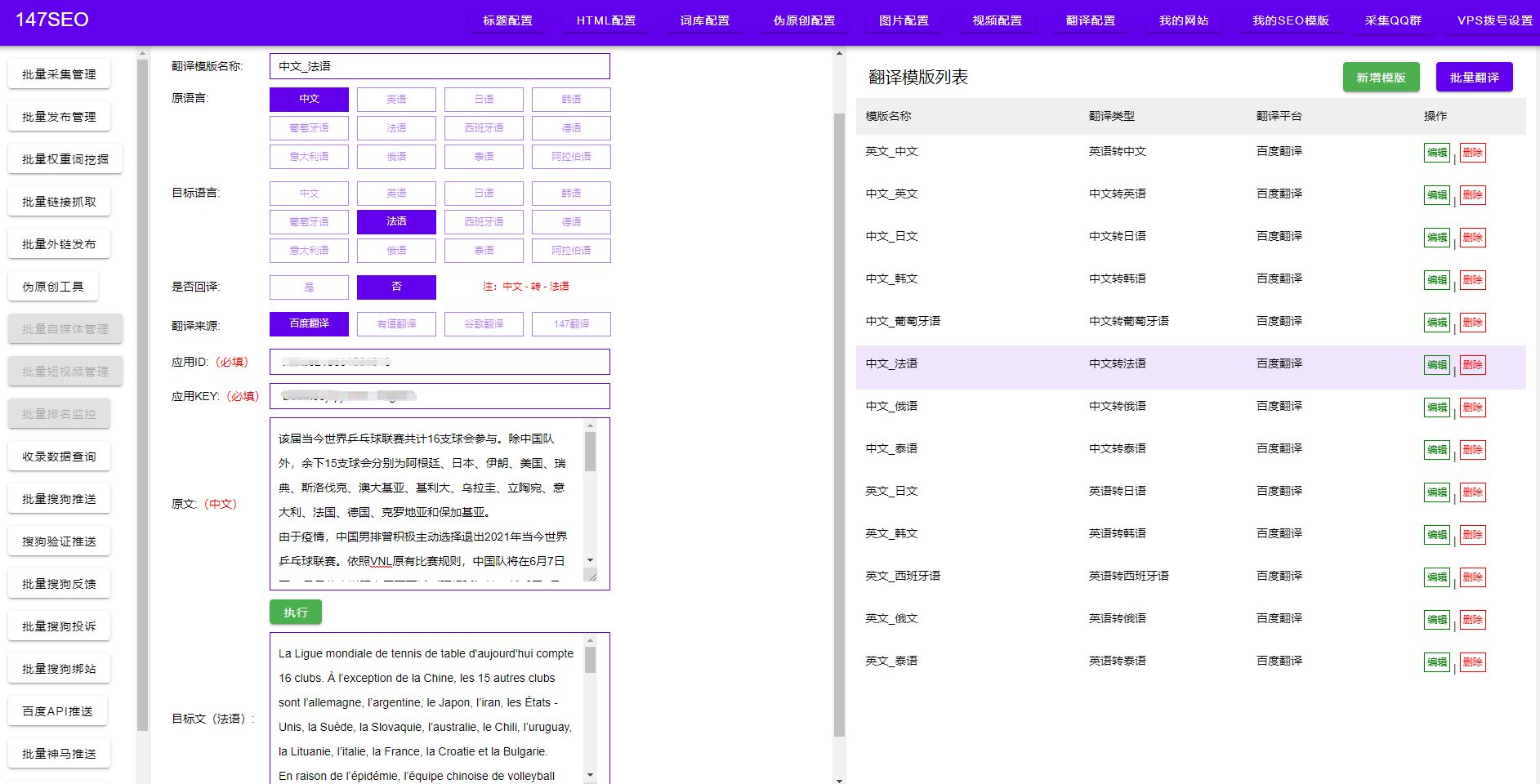
爬虫技术在当今大数据时代发挥着重要作用,它可以帮助我们快速获取大量数据,并进行进一步处理和分析。对于许多从事数据分析工作的人来说,掌握一些高效的爬虫技巧是非常必要的。本文将分享使用爬虫爬取10000条数据的步骤和方法,确保您能够轻松完成任务。

首先,为了高效地使用爬虫爬取数据,我们需要选择合适的工具和框架。Python是一种常用的编程语言,它有着丰富的爬虫库和框架,如BeautifulSoup、Scrapy等。根据具体需求选择合适的工具进行开发。
其次,我们需要准备好爬取的目标网站。需要注意的是,我们应该尊重网站的爬取规则,避免给目标网站带来过大的访问压力。确保自己的爬虫行为合法合规。
接下来,我们需要了解目标网站的结构和数据分页的方式。通过分析目标网站的HTML源码和URL结构,我们可以确定所需数据的位置和爬取方式。一般来说,我们可以使用XPath或CSS选择器来定位和提取需要的数据。如果目标网站的数据分页,我们可以通过分析URL参数的变化规律,来实现数据的批量爬取。
在编写爬虫代码之前,我们需要设置适当的爬取延时和请求头信息。延时可以避免过于频繁的请求,导致目标网站的拒绝访问。请求头信息可以模拟真实用户的请求,增加爬虫的隐蔽性,减少被反爬虫机制识别的概率。
接下来,我们可以编写爬虫代码并进行测试。在编写代码时,我们可以利用正则表达式、XPath或CSS选择器来提取所需数据,并进行清洗和格式化。需要注意的是,爬取的数据可能存在噪声和脏数据,我们需要设计相应的清洗机制来确保数据的准确性和一致性。
在部署爬虫之前,我们需要进行反爬虫策略的处理。一些网站可能会通过IP限制、验证码等手段阻止爬虫的访问。我们可以通过使用代理IP、设置重试机制或者使用验证码识别技术来绕过这些限制。
最后,我们需要进行数据存储和后续处理。可以将爬取的数据保存到数据库或者文件中,方便后续的数据分析和调用。如果需要对数据进行进一步分析,我们可以使用Python的数据分析库(如Pandas)来实现。
总结起来,通过选择合适的工具和框架、了解目标网站的结构、合理设置爬取延时和请求头信息、编写爬虫代码并进行测试、处理反爬虫策略、数据存储和后续处理,我们可以高效地使用爬虫爬取10000条数据。希望本文的分享对您的数据爬取工作有所帮助!



