
随着互联网的迅速发展,数据已经成为影响决策和发展的重要因素之一。为了获取更加准确和全面的数据,越来越多的人开始使用爬虫来采集各类信息。然而,尽管爬虫能够帮助我们获取大量的数据,但有时候爬取的数据却不够充实和丰富。
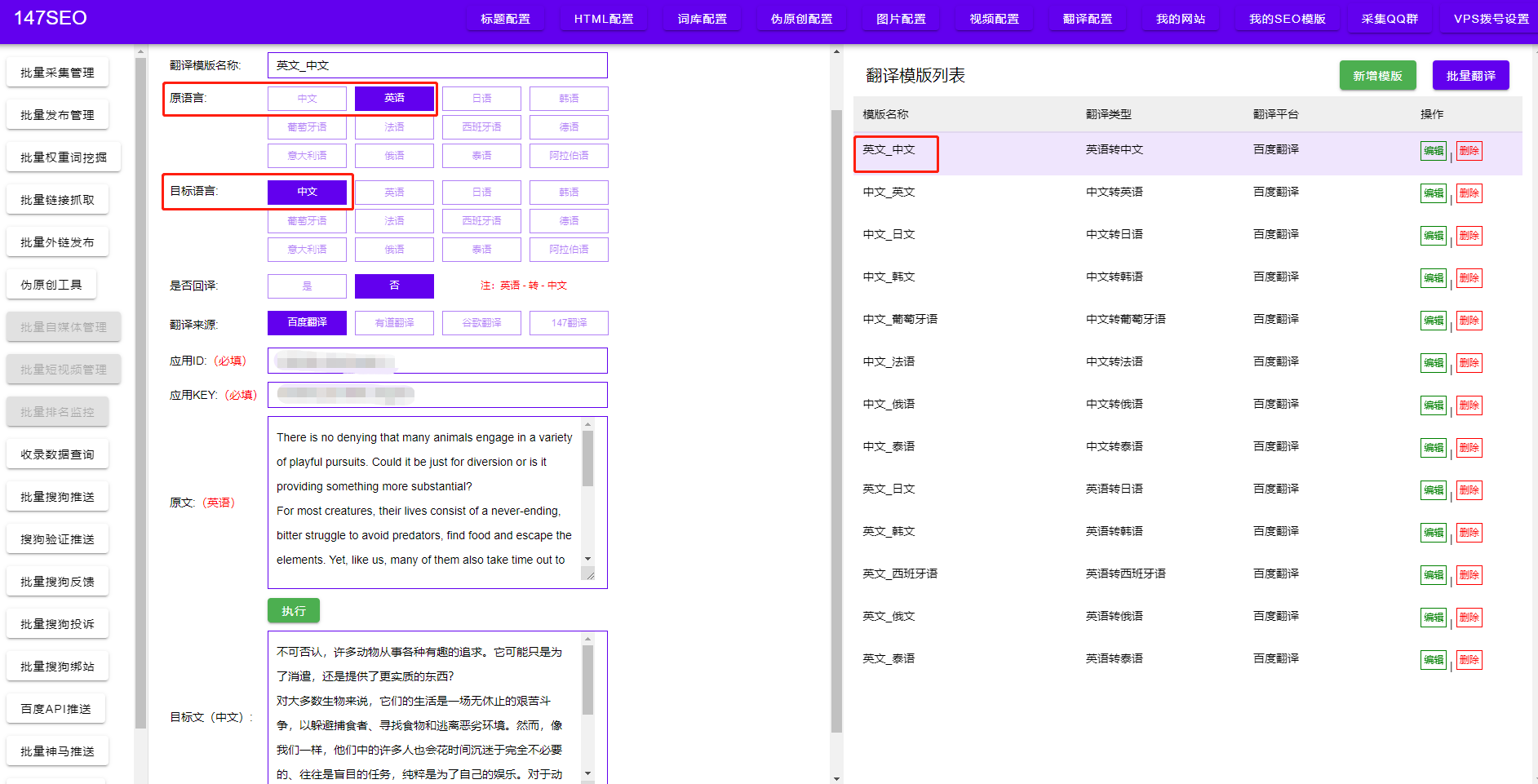
爬虫爬取的数据不够充实主要有以下几个原因:一是网页结构复杂,爬虫难以完全获取所有有价值的信息。有些网站会动态生成页面内容,或者有反爬机制,给爬虫带来了困难;二是爬虫的配置和参数设置不当,导致数据过滤不准确,获取到的信息质量较低;三是部分网站为了保护隐私或商业利益,对数据进行了加密或限制访问,使得爬虫无法获取全部所需信息。
要提升爬虫爬取的数据质量,我们可以采取以下策略:一是优化爬虫算法和程序,提高数据抓取的准确性和完整性。通过分析网页结构和动态页面生成的原理,我们可以针对性地优化爬虫程序,提升数据采集的效率和质量;二是合理设置爬虫的参数和配置,根据网站特点进行调整,过滤掉无关信息,只获取真正有价值的数据;三是与网站管理员或数据提供方进行合作,获取授权或协议,以合法方式获取数据,避免违反相关规则法规。
除了采取上述策略,我们还可以通过其他方式来获取数据,以充实软文内容。首先,可以寻找其他数据源,比如开放数据接口、公开数据集等,结合爬虫采集到的数据进行整合和分析;其次,可以与专业机构或领域专家进行合作,借助他们的经验和ZY,获取更加深入和专业的数据;最后,可以采用数据挖掘或机器学习技术,对已有的数据进行分析和处理,挖掘出隐藏的规律和价值。
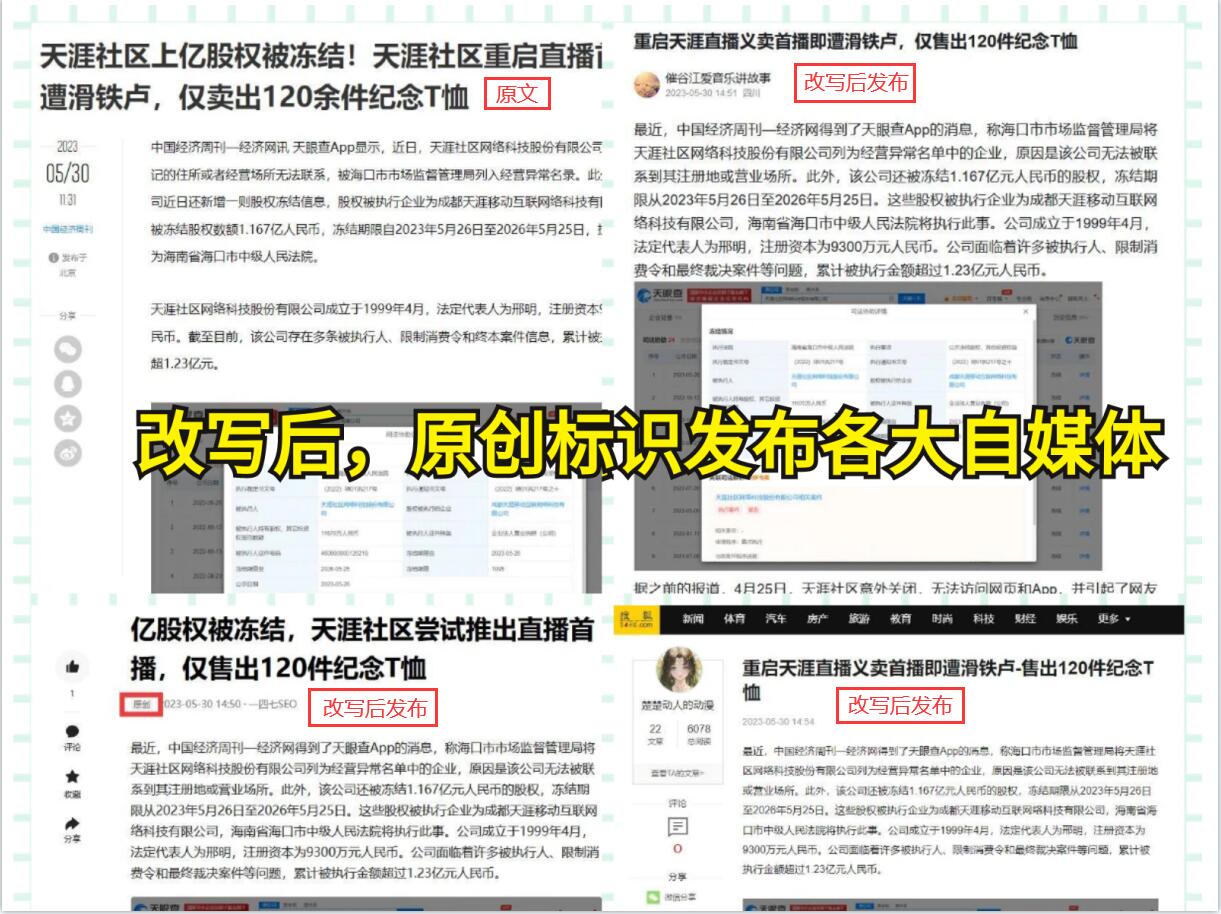
综上所述,虽然爬虫爬取的数据有时候不够充实,但我们可以通过优化爬虫算法和程序、合理设置参数和配置,以及与数据提供方合作,提升数据采集的质量。同时,通过寻找其他数据源、与专业机构合作和应用数据挖掘技术,我们也可以充实软文内容,提供更加有价值和可信的信息。在互联网时代,数据是驱动发展的动力,我们可以不断努力,让数据露水马蹄追,为互联网应用和决策提供更加可靠和有用的支持。



