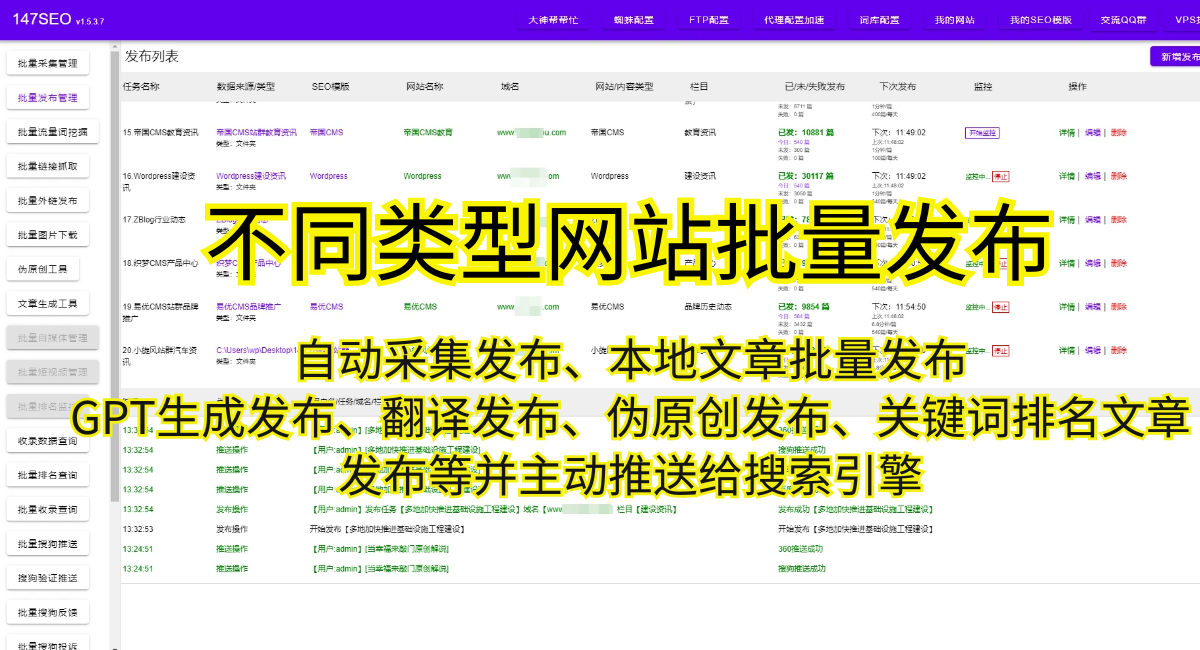
在当今信息爆炸的时代,海量数据的爬取和分析对于许多行业来说至关重要。那么,如何使用爬虫高效地爬取500万条数据呢?本文将为您介绍一些有效的方法和优化建议。
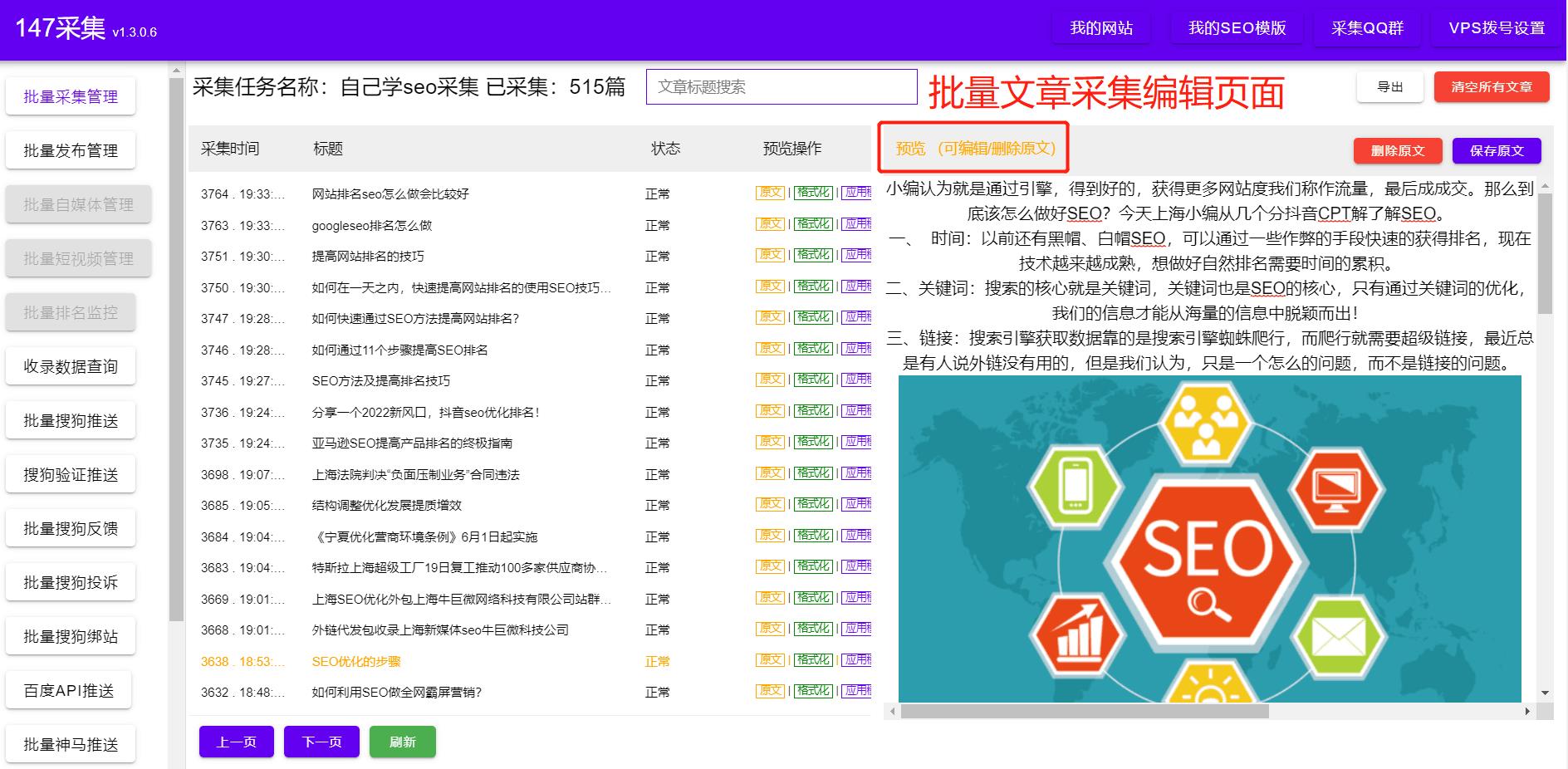
首先,选择合适的爬虫框架是非常重要的。目前,市面上有许多成熟的爬虫框架可供选择,例如Scrapy、BeautifulSoup等。这些框架提供了强大的功能和易于使用的API,能够帮助您快速构建和执行爬虫任务。
其次,合理设置爬虫的并发量和速度是提高效率的关键。爬虫可以通过多线程或异步网络请求的方式来提高效率。同时,合理调节爬取速度可以避免给目标网站带来过大的压力,避免IP被封禁。根据目标网站的响应速度和自身电脑的配置,合理调整并发量和爬取速度,可以大幅加快爬取数据的效率。
第三,合理制定爬取策略和优化算法也是提高效率的关键。在大规模数据爬取过程中,可以考虑使用分布式爬虫架构,将任务分解到多个节点上并行处理,以快速完成数据获取。此外,可以根据目标网站的特点,制定有效的爬取策略,例如使用请求头伪装、设置数据请求间隔等,以规避反爬机制或请求频率限制。
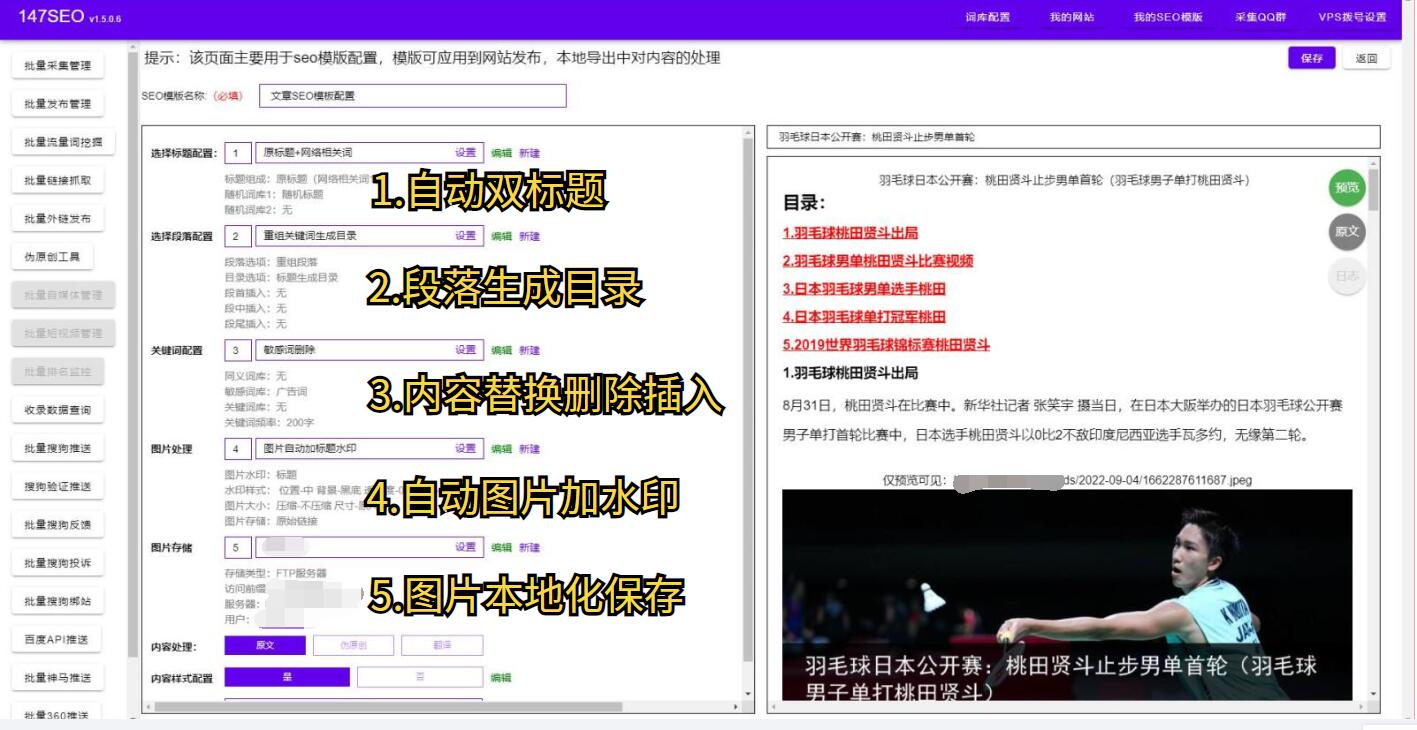
此外,对爬取到的数据进行预处理和优化也是非常重要的环节。爬取到的数据可能存在重复、噪声或无效信息,需要进行数据清洗和筛选。同时,可以使用存储优化算法,如使用压缩算法或数据库索引等,以减小数据占用空间并提高查询效率。
总结一下,要高效地爬取500万条数据,首先选择合适的爬虫框架,其次合理设置爬虫的并发量和速度,然后制定适合的爬取策略和优化算法,并对爬取到的数据进行预处理和优化。通过这些方法和建议,您可以提高爬取数据的效率,更快地获取所需信息。
希望本文的介绍能够对您在爬虫领域有所启发和帮助。如果您对爬虫还有更多的疑问或需要更深入的指导,欢迎咨询我们的专业团队,我们将竭诚为您提供支持和解答。