
玩转Python,轻松爬取网站数据
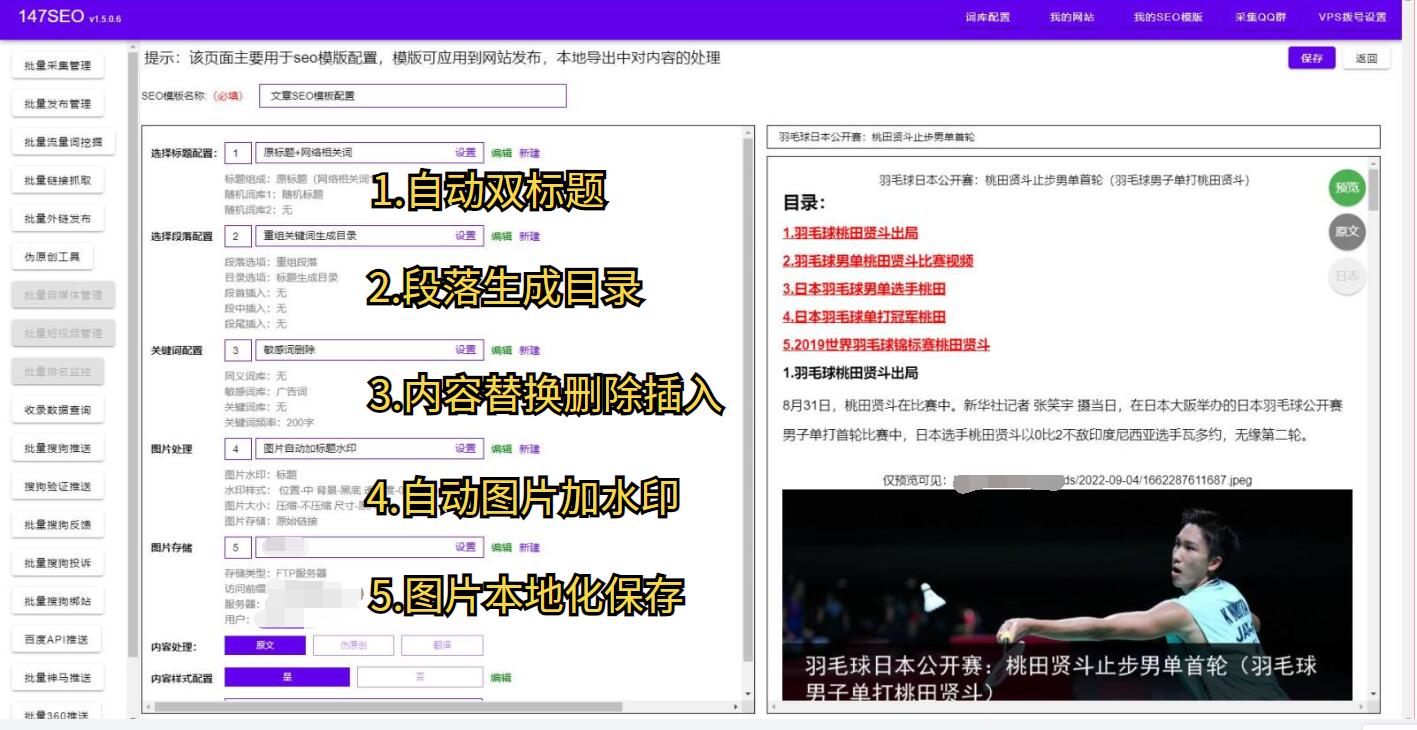
随着互联网的快速发展,数据已经成为了当今社会的重要ZY,深入了解和分析数据能够帮助我们做出更明智的决策和发现潜在商机。而对于从网站上获取数据,Python通过其强大的网络爬虫库成为了首选的编程语言之一。
Python作为一门简洁、易用且功能强大的编程语言,提供了丰富的库和工具,可以用于各种应用场景。使用Python进行网站数据爬取可以帮助我们快速获取所需的信息,进而进行数据分析和挖掘。
在使用Python进行网站数据爬取之前,我们首先需要了解一些基本概念和技术。网络爬虫是一种自动化地浏览和获取网页内容的程序,它通过模拟用户访问网页的行为,获取网页的HTML代码,并从中提取出所需的信息。常见的网络爬虫工具包括BeautifulSoup、Scrapy等。
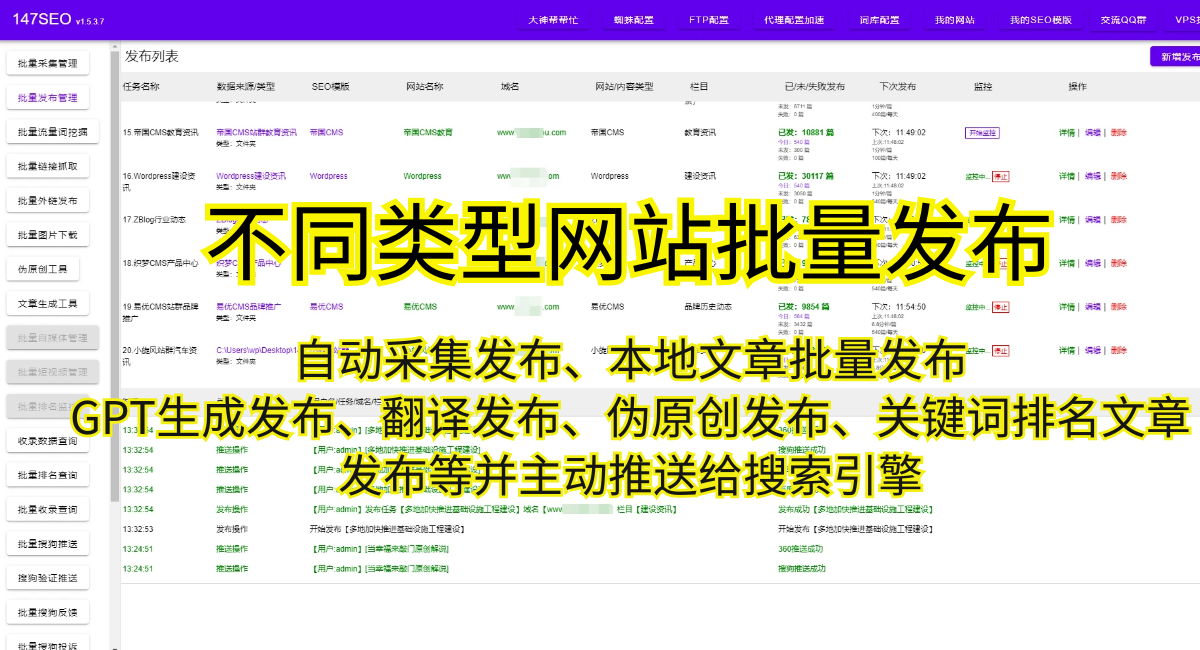
接下来,我们将介绍使用Python编写网络爬虫的基本步骤:
1.确定爬取目标:首先需要确定需要爬取的网址和所需的数据类型。这一步需要明确我们希望从网站上获取哪些信息,例如标题、日期、内容等。
2.分析网址和网页结构:爬取数据之前,我们需要分析目标网页的结构和HTML代码。可以使用浏览器的开发工具或者相关的网络爬虫库来实现。
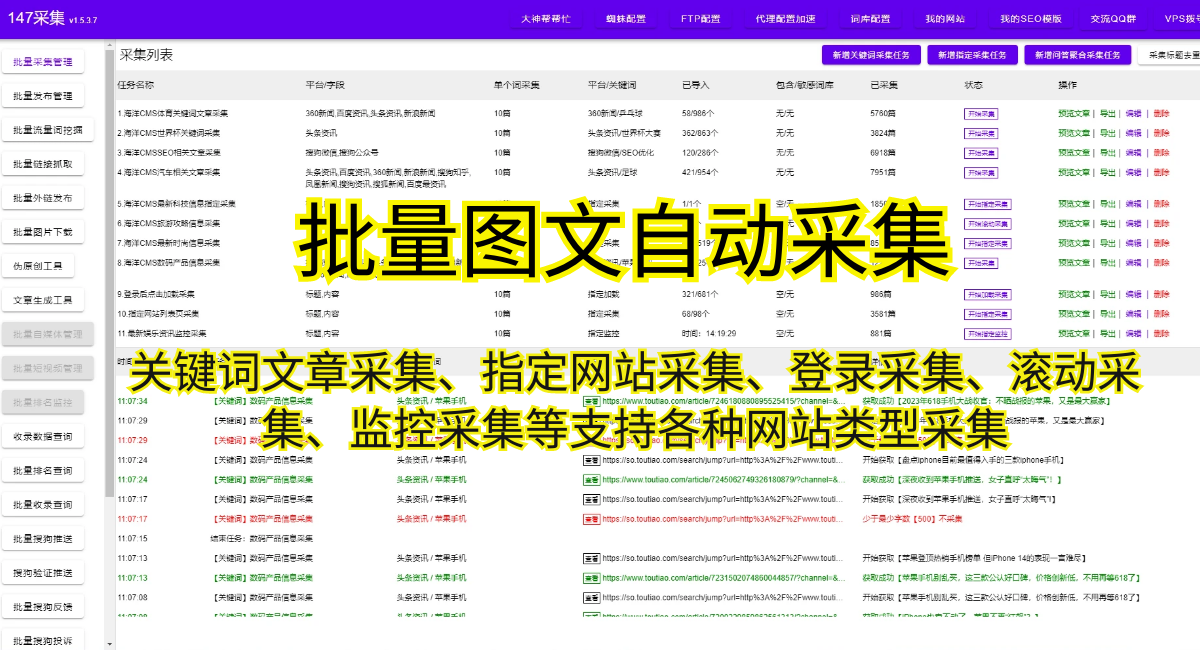
3.编写爬虫代码:在Python中,我们可以使用requests库来获取网页内容,再使用BeautifulSoup库来解析HTML代码并提取所需的数据。此外,还可以使用正则表达式或者XPath来实现更加高级的数据提取操作。
4.数据存储和处理:获取到所需的数据之后,我们可以选择将其存储到数据库或者文件中,并进行进一步的数据处理和分析。
使用Python进行网站数据爬取的好处不仅在于其丰富的库和工具,还体现在以下几个方面:
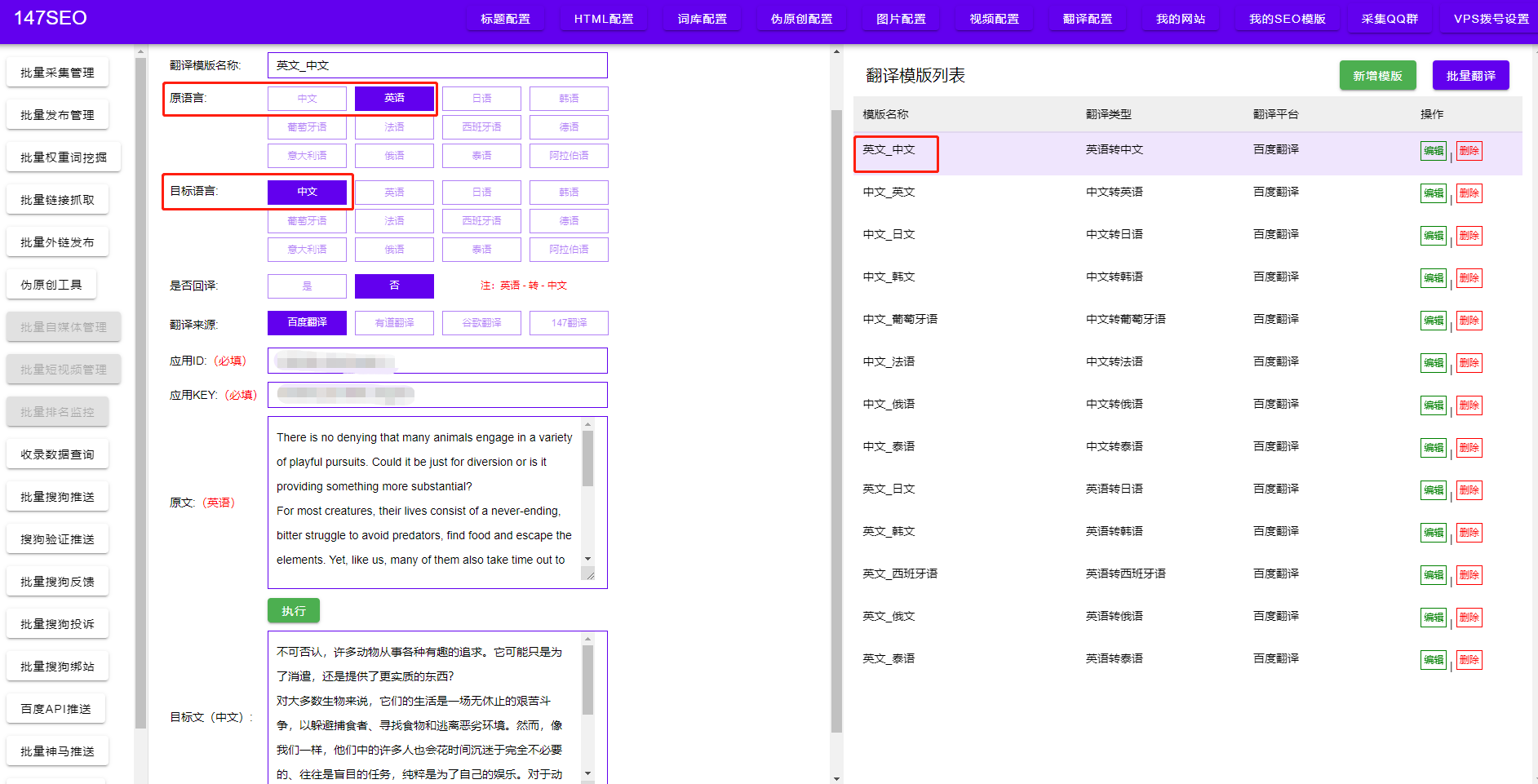
1.易于上手:Python语法简单易懂,学习门槛较低,即使是没有编程经验的人也可以轻松上手。
2.可扩展性强:Python拥有丰富的第三方库和工具,可以满足各种需求,包括网络爬虫、数据处理、数据可视化等。
3.网络爬虫框架:Python提供了多个网络爬虫框架,如Scrapy,可以帮助我们更快地开发并运行高效的爬虫程序。
4.广泛应用:Python在数据分析和挖掘领域被广泛使用,因此对于想要进一步了解数据相关知识和技能的人来说,掌握Python的数据爬取技术将是一项有用的技能。
总结起来,利用Python进行网站数据爬取可以帮助我们快速获取所需的信息,并为后续的数据分析和挖掘提供支持。掌握Python网络爬虫的技术,对于数据工作者和数据爱好者来说都是一项有价值的技能。希望本文能够帮助到您,让您轻松玩转Python,实现对网站数据的灵活获取和利用。



